DesignerNew features 🎉
No more mysteries about what went wrong or right during your data transformations! Matillion's new data lineage functionality is currently in public preview in transformation pipelines, with orchestration lineage coming next down the line. You can now track an entire pipeline from source to target, allowing you to see the flows of data, and better understand relationships and transformations. Data lineage in Designer provides:
- Transformation lineage at runtime.
- Table-level lineage.
- Column-level lineage.
- Visibility into joins where tables are connected.
- Table lists.
- Table metadata—column information and data types.
- Metadata about a pipeline run (when it ran, how long it took, who ran the pipeline, and success/fail).
Whether you're interested in confirming data quality, ensuring compliance, improving troubleshooting, or just efficient data processing, data lineage in Designer gives you a massive new window looking into the flow of data through your pipelines.
"We're transforming our observability capabilities with integrated lineage, providing end-to-end visibility and traceability of data journeys to empower organisations with greater insights, accountability, and efficiency in their data integration processes."
— Lee Power, Senior Product Manager at Matillion
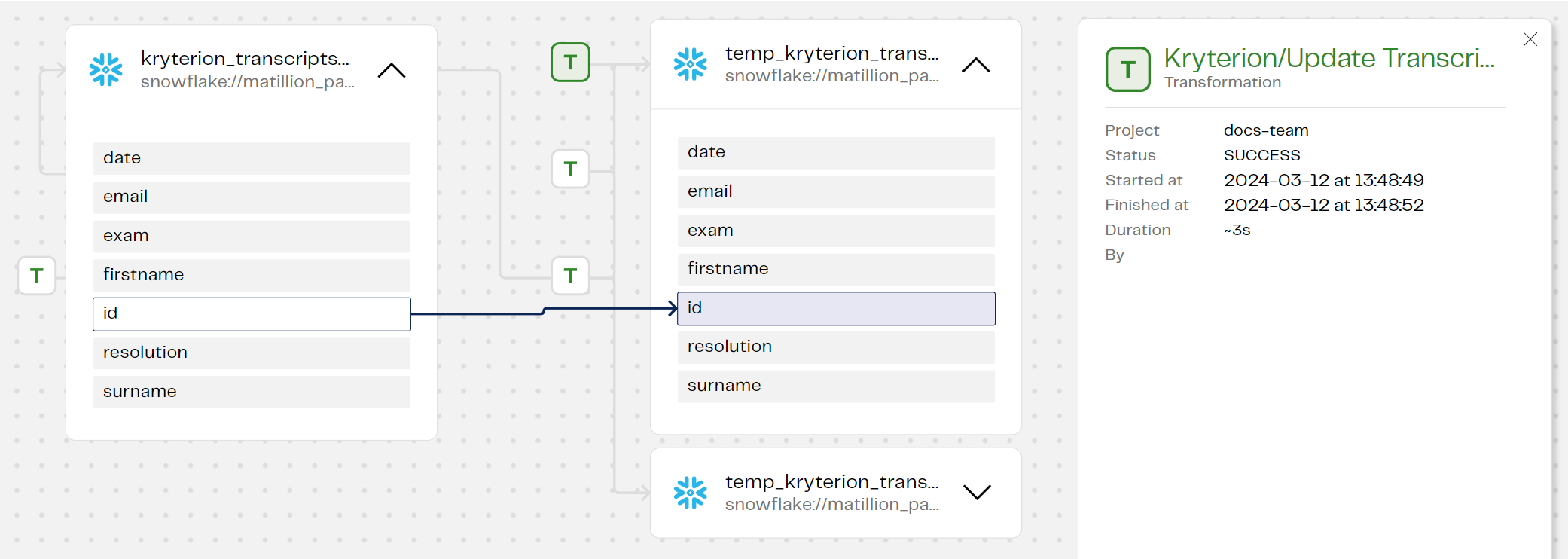
To get started, from the main menu click "Manage", then "Pipeline Runs", and finally "Lineage" to see data lineage for your recent transformation runs. You may need to run your transformations again to see them in lineage.
See the documentation for all the details.
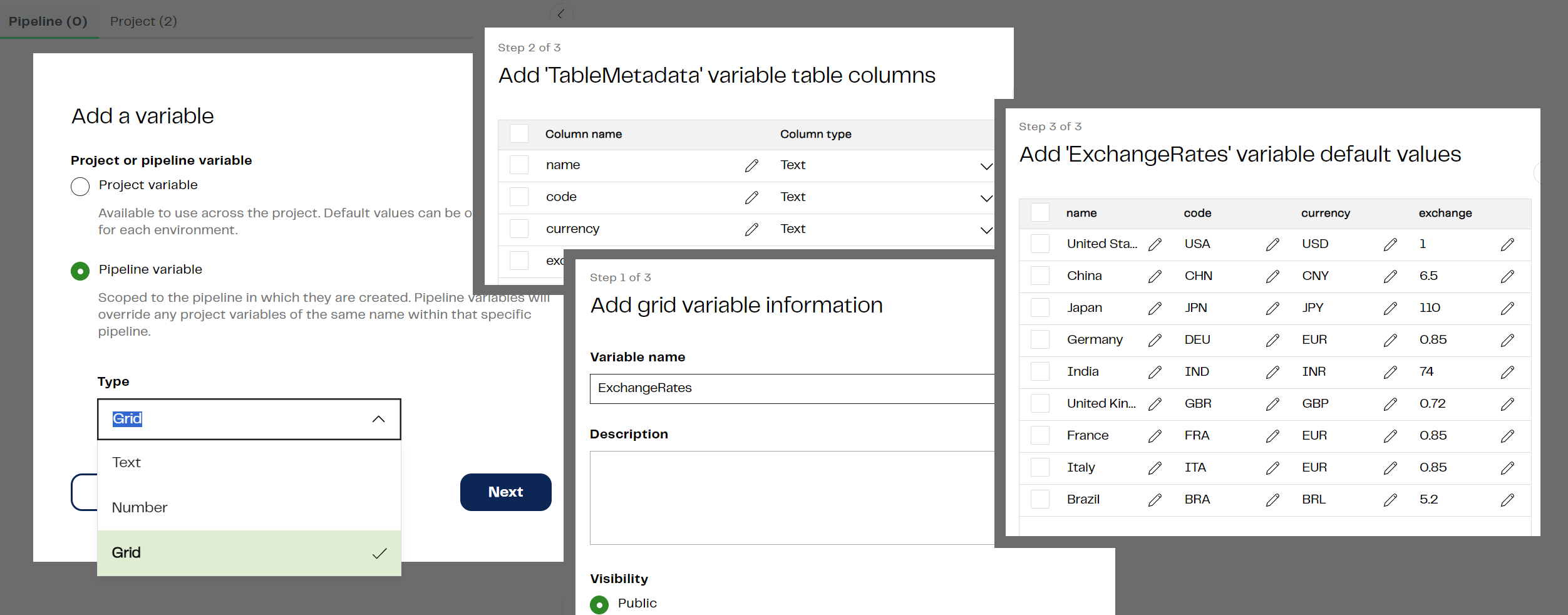
Dear customers, we love you and we love to hear what you want most. That's why we're so excited to announce that you now have the ability to enter column information and grid variable fields in text mode. It's so much faster now to add information to a property dialog. Instead of typing or selecting values in the individual fields of the dialog, you can click the Text mode toggle to open a multi-line editor that lets you add all the items in a single block.
What about error handling? Well, after you've entered details in text mode, you switch out of text mode to verify the details are valid before you continue. Don't worry: text mode will tell you if you mistyped!
You can use this feature to edit the fields of an existing grid variable or Columns dialog, regardless of whether the columns were originally completed in text mode or not. Perhaps most satisfying: text mode allows you to paste in values from other text sources. You can also rapidly copy the fields from a completed grid variable or dialog, enabling easy duplication of properties between or within components and grid variables.
For details, see Components overview and Creating grid variables.
More exciting news: we've just added these Flex connectors for developing data pipelines: