Batch load replication overview
Batch Loading enables the user to extract data from any source supported by the product and load that data into their chosen cloud data platform with minimal configuration and complexity. This saves time in terms of data preparation, allowing businesses to move enormous amounts of data into the cloud to analyze and gain insights fast.
Features
Batch Loading provides a fully SaaS data loading experience to extract and load data at user specified time intervals from sources as diverse as Salesforce, Facebook, Google Analytics, Postgres, MySQL, Excel or Google Sheets, to cloud data platforms such as Snowflake, BigQuery and Redshift. Incremental loading using a high-water mark is also supported dependent on your source data models to provide only changed data after the initial load.
Key features of Batch Loading:
- Batch loading is ideal for processing large volumes of data with minimal configuration required. It also increases efficiency by using incremental loading (if the source supports this) based on a high-water mark strategy, ensuring that only changed data is loaded on your desired frequency post an initial load.
- Simplifies ingestion into Big Data platforms from multiple disparate sources.
- Using Data Loader - no coding is required. The ELT processes dynamically handle the batch loading as per the configuration supplied so you can spend time on getting valuable insight from your data in the cloud.
- Moving data to a cloud data platform empowers distributed analytics teams to work on common projects for business intelligence.
Batch Loading Process
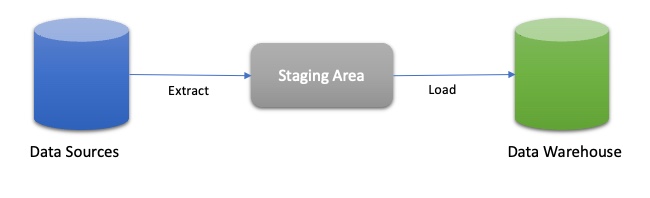
- The ELT process will extract the tables and columns as specified in your configuration from the data source, applying any additional conditions as required by your source connector.
- The data is staged into your chosen cloud storage area and then loaded to the target cloud data platform. Audit columns are added (a batch ID and update timestamp) to facilitate traceability before the staged data is written to the final target table.
- Cloud storage: For Amazon Redshift and Delta Lake on Databricks, Amazon S3 storage is used; for Snowflake, Snowflake Managed Staging is used, which uses internal snowflake stages on your chosen cloud storage area (AWS S3, Google Cloud Storage or Azure). For BigQuery, Google Cloud Storage is used. All data is purged from your cloud storage as part of the ELT process.
- If your source supports incremental loading, the initial batch run will load all data as specified. After that first run, data is then incrementally loaded using the defined high-water mark (incremental column) and primary keys. Dependent on the type of source, this may be done automatically by the ELT process (for known data models, such as Salesforce or Facebook, for example) or you specify the high-water mark (incremental column) and primary keys to control how the process defines a change data set.
- You can schedule your pipeline to run on a frequency of minutes/hours/days, from a minimum of every 5 minutes to every seven days.
- You can use the audit columns added by the ELT process to add audit and traceability screens to downstream functions.
To build a pipeline with batch processing, you need to:

- Select the source from the pool of supported data source.
- Select Batch Loading as the ingestion method (where CDC and Batch are both offered).
- Select the table and column you would like to extract.
- Choose the destination data warehouse.
- Configure the required details for the data warehouse access.
- Provide the additional pipeline settings, set frequency and schedule the pipeline run.
Note the following:
- You will need to be able to access and authenticate the data source with a username/password or OAuth.
- You will need to access and authenticate your target data warehouse with a username/password.
- You must have sufficient permissions to make required changes in the databases and destination data warehouses. We recommend that you contact your database administrator to confirm your access and permissions.
- Determine the frequency of updates in pipeline settings.
If you are looking to do even more with your data, we offer a seamless transition to Matillion ETL, which allows for complex transformations.
Core Concepts
There are some important concepts to understand within the Data Loader Batch Loading feature. These are detailed below:
Pipelines
A pipeline is a collection of configuration details including the source configuration, destination configuration and any advance properties that are used to process data in batches and load them to the appropriate data warehouse.
Sources
The source (or source configuration) is a collection of connection properties for the source database you wish to configure a pipeline for.
Destinations
The destination (or target/target configuration) is a collection of properties where the data fetched from a source is loaded. Please refer to the list of supported destinations for batch loading.