Adding Filename as a column to new table🔗
Overview
A question we are often asked is how to add the source filename as a column in the Redshift table. Unfortunately the Redshift COPY command doesn’t support this; however, there are some workarounds.
This article covers two ways to add a source filename as a column in a Snowflake table.
Option 1 - Using a File Iterator to write the filename to a variable
The File Iterator component is used to loop through all files in a location and write the names to a variable. The File Iterator can be configured to point at one folder in an S3 Bucket and it identifies all files that match the regex.
In the File Iterator properties, the Input Data Type is S3, and the Input URL is the folder on the S3 Bucket where the data files are held:
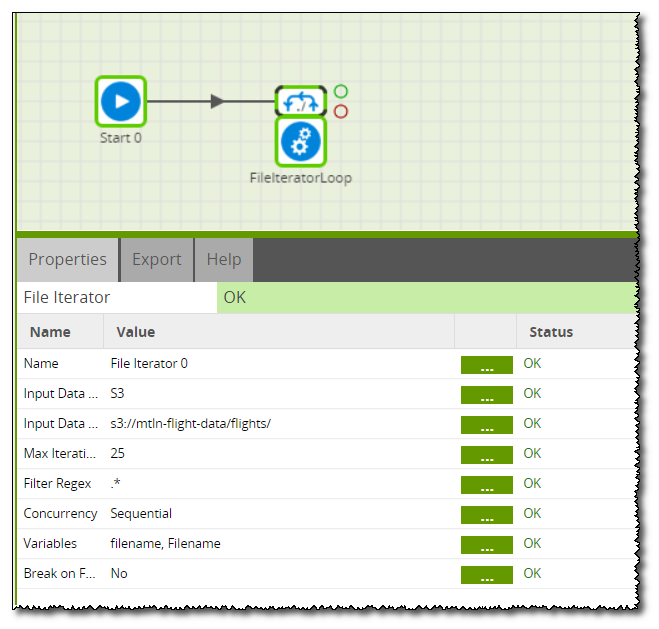
The final step on the Iterator is to configure the variables. This example uses a Shared Environment Variable called filename and this is pointed at the filename returned from the File Iterator:

The File Iterator is connected to an Orchestration job that contains the S3 Load and a Transformation job. The S3 Load is configured to Load the file with the filename received from the iterator into a temporary stage table:
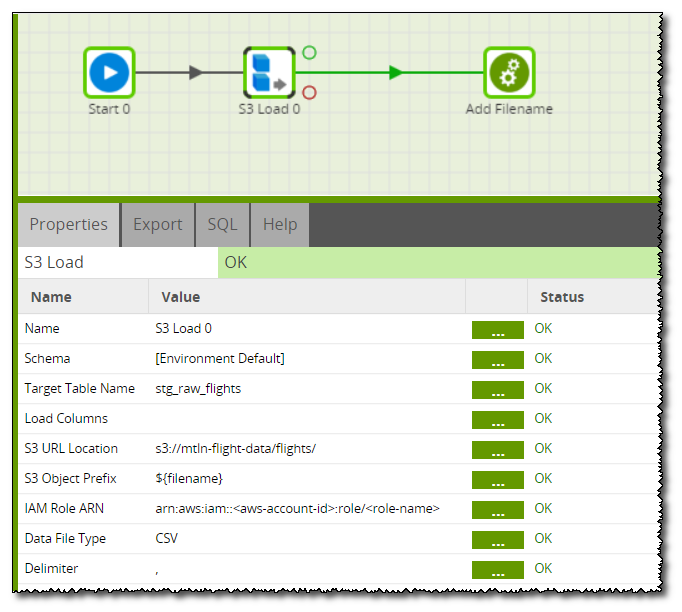
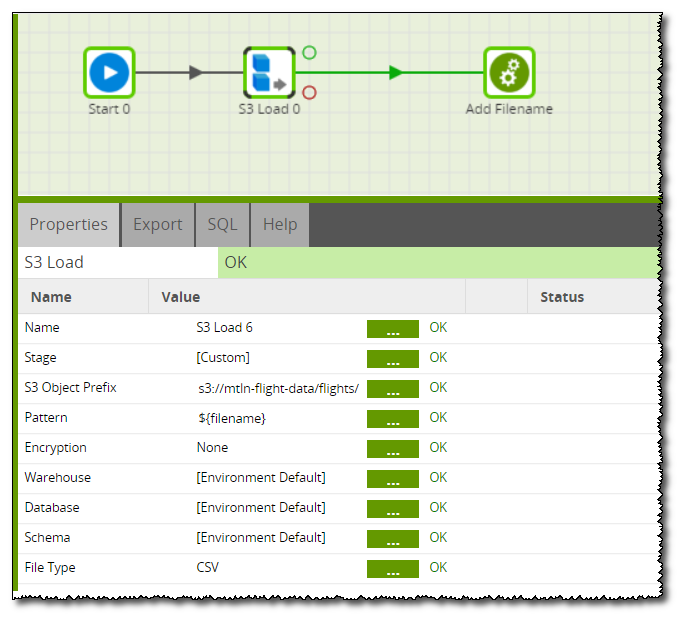
The Transformation job simply takes the data from the stage table, uses a calculator to append in the new file name, and then uses a table output to write it to a new table with the filename:
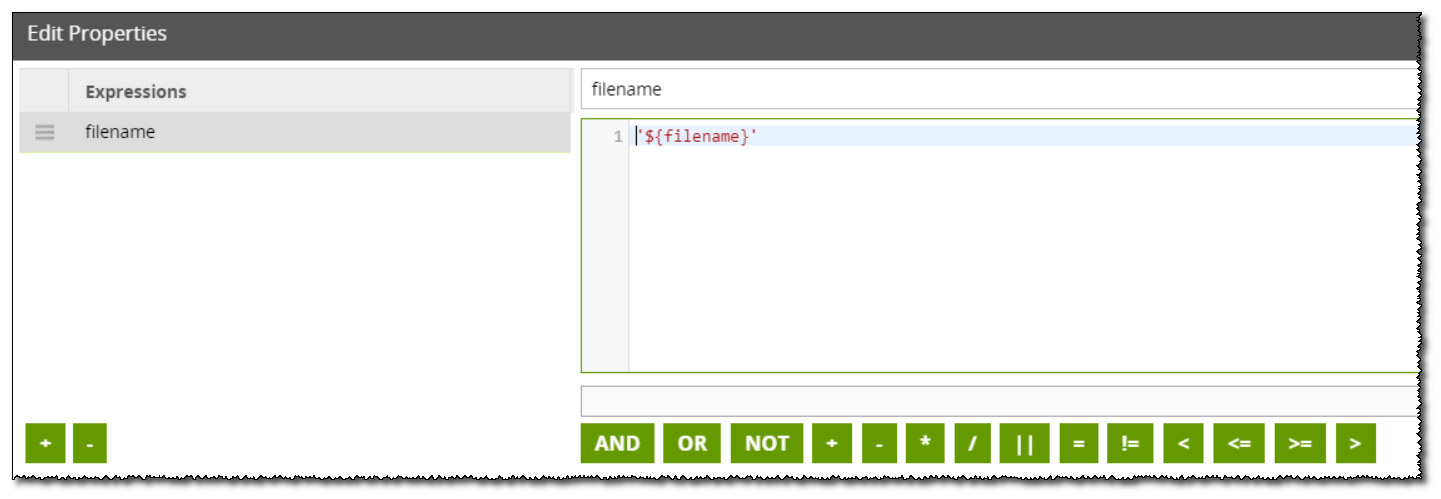
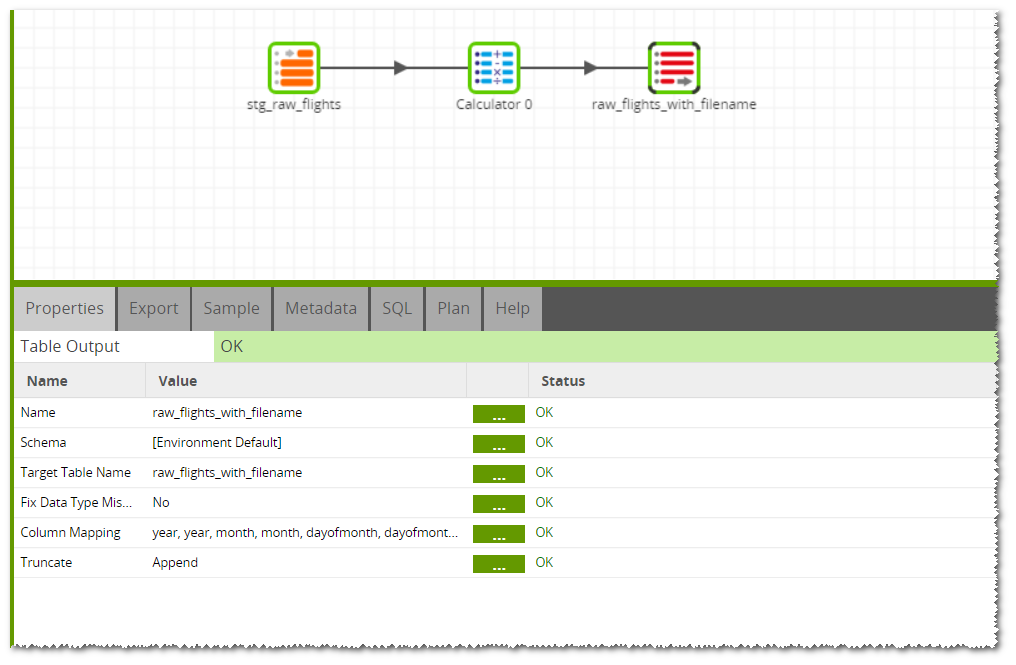
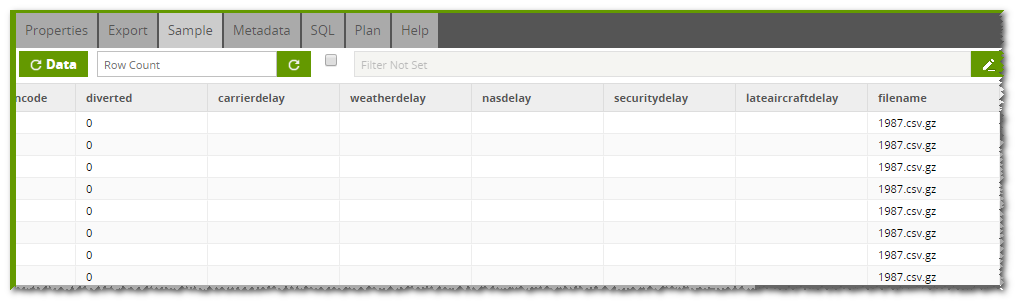
When the job is run, the File Iterator will grab the first file and set the name of it into the variable. The Loop Orchestration job will then load the data from that file into a stage table and then call a Transformation job. The Transformation job will then load the data from the stage table into a permanent table and will use the calculator component to take the variable value containing the filename, and add it into a new column:
Option 2 - Using a Lambda Function
There may be some instances where it’s not possible to use a File Iterator to pick up the file name, for example when a manifest file is used. Another option, therefore, is to load the data by a Lambda Function and pass through the filename. This article talks about how to set up a Lambda Function based on an S3 Trigger.
The first step is to configure a Lambda Function to put a message on an SQS Queue when a new file is added into the S3 Bucket:
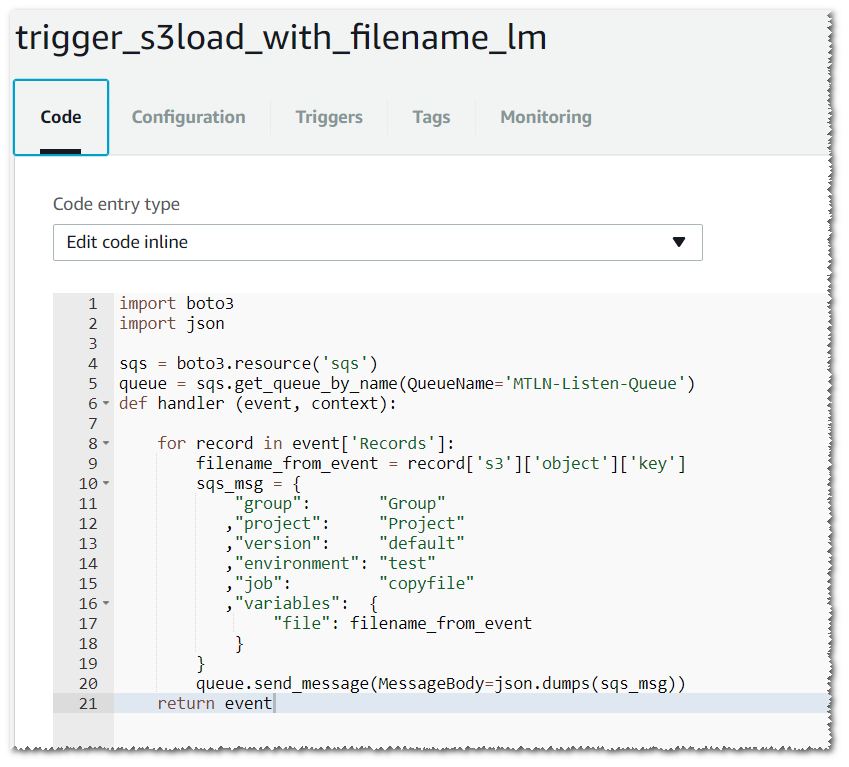
The SQS message is passing a variable called file.
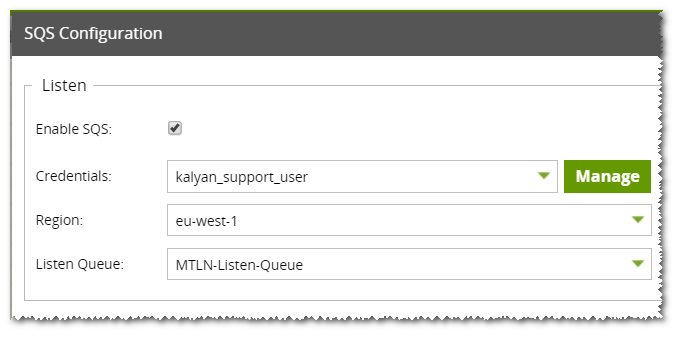
Matillion ETL is then configured to listen to the SQS Queue. Further details on configuring Matillion ETL to listen to an SQS Queue are available here.
An Orchestration Job is then used in Matillion ETL to load the content of the new file into a staging table and then a Transformation Job is used to add in the filename from the variable using the same method as option 1:
The Copy command doesn’t include the option to add the filename to the table created, hence the Matillion ETL S3 Load component doesn’t support adding the filename to the table. However, this article covers 2 examples of how to use other Matillion ETL components and AWS services as a workaround to include the filename.
A copy of the job used in this article is available for download below.