Using Spectrum in Matillion ETL🔗
Overview
In this article we will take an overview of common tasks involving Amazon Spectrum and how these can be accomplished through Matillion ETL. If you have not already set up Amazon Spectrum to be used with your Matillion ETL instance, please refer to the Getting Started with Amazon Redshift Spectrum documentation.
Amazon Spectrum is a layer that sits on top of Redshift and allows Redshift tables to store references to data held on S3. This means that large amounts of data can be held outside of Redshift where space is at a premium but still exist in a table that can be manipulated. Tables that reference externally held data like this are termed 'External Tables'.
The below sections briefly discuss common Matillion ETL tasks associated with Spectrum.
Creating a new External Table
Use the Create External Table component as part of an orchestration job.
Setting the Create/Replace property to Replace to overwrite a table when writing a new table of the same name.
Note: These will create new Redshift tables that reference a given S3 Location. They do NOT create anything on S3 at this point and thus the tables are essentially empty unless their referenced location already houses external data with the same metadata. You can use the S3 Unload or S3 Object Put component to load the S3 location with data that your new table will then be able to access.
Writing an external table from data in Redshift
Redshift tables can be read, created, transformed, written and overwritten inside Matillion ETL using Transformation jobs. Writing an external table here is a little different to creating a new external table as we can assume there will be some data inside these tables, which means it must be placed on S3.
Using the External Table Output component will append existing external tables using a column mapping of the user's choice. This means it will also write and append data on S3 at the location that table references (usually set when the table is created).
Using the Rewrite External Table component write a new (or overwrite an old) external table and data on S3, making it potentially destructive on both Redshift and S3.
Note: Partition columns can be given on Rewrite External Table as it is always a new table. This is not true for External Table Output which is generally focused on appending existing tables.
Referring to External Tables in scripts
External tables can be referred to in SQL scripts like a regular tables. Care should be taken to state that the table belongs to an external schema using 'dot notation'. For example:
SELECT * FROM "external"."salesdata"
Where external is the name of our external schema and salesdata is the name of our external table.
Deleting External Tables
The ability to delete external tables through Matillion ETL's Delete Tables component is coming soon. Until then, it is suggested that external tables are deleted using the SQL Script component using a DROP TABLE command. For example:
DROP TABLE "externalschema"."externaltable"
Partitioning data
Partitioning data on Redshift requires 3 things:
- An external table with one or more partition columns.
- Data on S3 that is stored in folders named using a particular partition key and value.
In Matillion ETL this generally means:
- Use the Create External Table component to make a new external table WITH one or more partition columns defined.
- Use S3 Unload (or S3 Put Object) to place data in an S3 Location that matches your expected partition key:value combination (see below).
- Use the Add Partition component to create partitions on the external table on one of the partition columns you defined previously.
Your partition key:value combination is what a partitioned column expects the S3 endpoint to be named and will reference according to that name. Its format is:
<key>=<value>
The 'key' is the name of your partitioned column. The 'value' is the value in that column you wish to partition by. Thus the format is akin to:
<columnname>=<partitionedvalue>
For example: We have a table and want to partition it by the 'year' column. Our table has many rows but all years are either 2010, 2011, 2012. This means we can have 3 potential partition key:value combinations:
year=2010 year=2011 year=2012
To create these 3 partitions, we need to create an external table with 1 defined partition column (year).
We then create 3 folders with the above names at our desired S3 endpoint.
Finally, we create 3 partitions, one for each of those endpoints.
To write data from a Transformation job as partitioned data, the Rewrite External Table component must be used. Note that this allows far less control over the partitioning of data and will simply create a partition for every unique value in the given partition column.
Deleting Partitions
Partitions can be removed from an external table using the Delete Partition component. This will remove a particular partition but does not change which columns are defined as partition columns on the table.
This does not remove data from S3 associated with that partition. To remove S3 data from within Matillion ETL, consider using a Bash Script component. For example:
aws s3 rm s3://bucketname/foldername/partition/ --recursive
Example
In this example, we will be taking a large amount of data that is to be partitioned by year and month. The job assumes that each run has a unique data set (no historical data that will cause duplicates when appended).
This job will be briefly discussed below and is downloadable for importing into Matillion ETL at the bottom of this page.
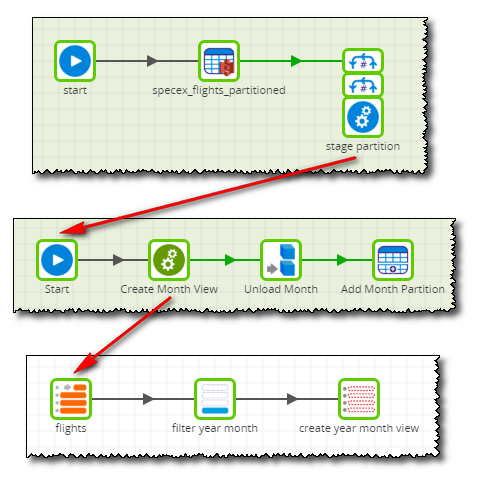
The example workflow is split into 3 jobs. An external table is (re)created and we loop through a range of years and months of our choosing - typically we might choose every year since our data began and all 12 months. A view is then built using data filtered by year and month and used to upload data from Redshift to S3. Finally, our external table is partitioned to match our S3 data.
Note: In this example, we assume all incoming data is unique and will not cause duplicate entries with previous runs of this job. If you have one large dataset containing new and historical data, it is advisable to add a Bash Script component to remove existing S3 data before continuing, as shown below.
Back to our main job, the first section (an orchestration job) begins with the Create External Table component which is set up as shown below.
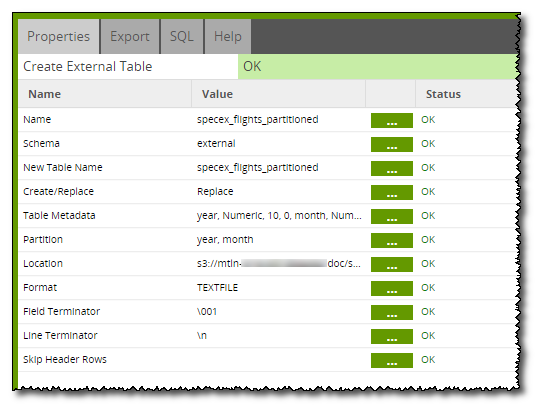
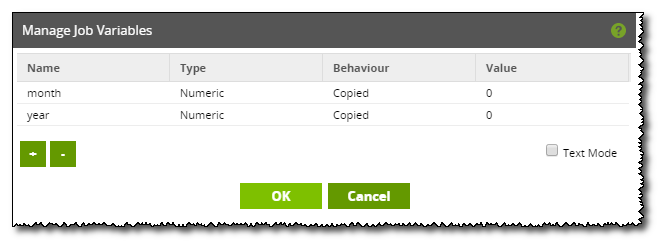
The table is set to replace any existing tables and has its 'year' and 'month' columns defined as partition columns. After this, 2 nested Loop Iterator components are used to go through a range of years and all months. These loops use the variables 'year' and 'month' as their iterated value, which is passed to the called Orchestration job. These job variables must be set up in each of the jobs included.
The called job does only two things: call a Transformation job, followed by running an S3 Unload component.
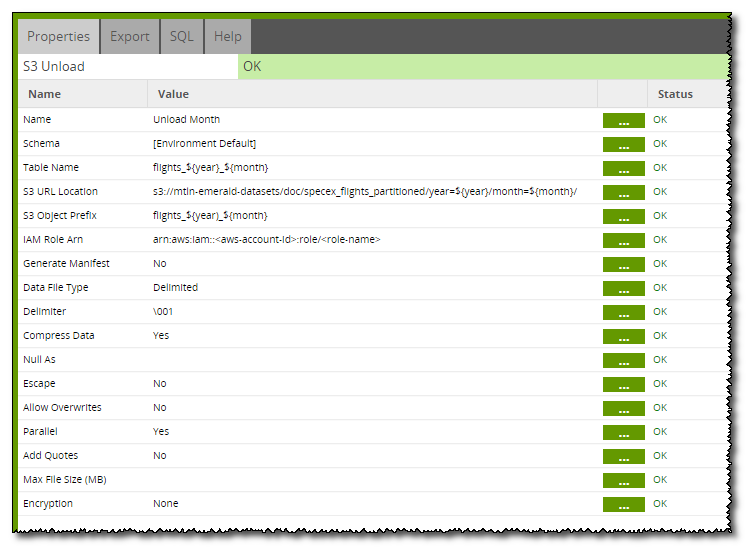
The S3 Unload component will place data that exists on Redshift into S3. Note that the S3 URL Location utilises the month and year variables that we are iterating through to create key:value pairs. An example S3 URL Location might end up being:
s3://mtln/doc/specex_flights_partitioned/year=2010/month=2/
So here we have data partitioned by year, then further partitioned by month.
This uses a view that was created just one step before the S3 Unload component runs. A transformation job is called to take in all the data, filter it by the current iteration's year and month, then create a view based on the remaining data.
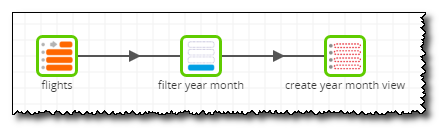
The created view is used is named flights_${year}_${month} and so one view is made for every partition. This view is then used in the 'Table Name' property of the S3 Unload component to take the filtered data and unload it to the S3 partition.
Now with the external table created and the data on S3, all that is left is to add partitions to the external table. Add Partition is the final component in the workflow, being called just after S3 Unload. There are two partition columns on the table, year and month, which are now given partition values, $year and $month, respectively (whose values depend on the current iteration).
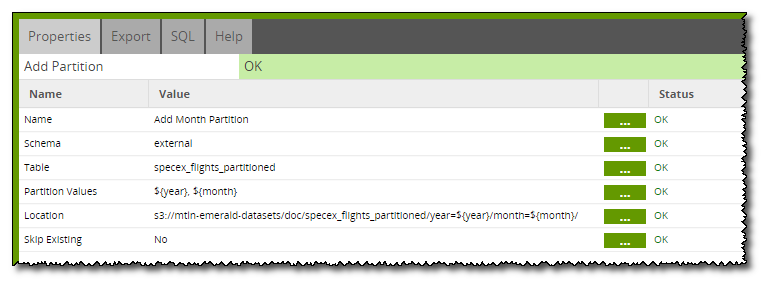
The location is set to the same location as we entered for the S3 URL Location set in the S3 Unload component, thus linking this partition on the external table to the s3 data.