Building a data vault (Snowflake)🔗
Overview
This document demonstrates how to implement a simple Data Vault model in Matillion ETL using the following three-tier data architecture:
- Staging: transient data, loaded either fully or incrementally from external sources
- Data Vault: the middle tier data structures (i.e. the enterprise data warehouse)
- Star Schema: the data presentation layer, for use in reporting and analytics

Data vault architecture
Important Information
- This document utilises a publicly available civil aviation dataset throughout, and this is available for download as part of this document.
- Data Vault techniques have been used to model the middle tier, rather than an alternative such as third normal form (3NF).
Warning
The attached JSON file should only be used as an example as it was built using Matillion ETL for Snowflake 1.44.11 and some components may currently be out of date.
Data Vault Explained
A Data Vault is a data modeling approach, typically used to design relational tables in an enterprise data warehouse. A specialized form of 3NF modeling, a Data Vault requires all objects to be broken down into their base parts and assumes all relationships may be many-to-many. This approach addresses some of the limitations of other commonly used approaches:
- Two-tier ("Kimball" style): considered inflexible and costlier to maintain
- 3NF middle tier: can be difficult to adapt to business changes, especially when source systems are altered, and can become abstract and difficult to interpret
A Data Vault primarily focuses on the core concepts of the underlying business. In the example, these concepts include "flight", "airport", "passenger" and "aircraft". These are broken down into their base parts, and these parts are defined by three types of relational database tables, namely Hub, Link and Satellite tables.
Relational Database Tables
Hub |
Link |
Satellite |
|---|---|---|
 |
 |
 |
|
Hub tables represent the central theme of a relationship. Records are identified by a natural business key, expressed in a way that anyone working in the business could understand—for example, an "aircraft" would be uniquely identified by its tail number (multi-part identifier can also be used). |
Link tables represent links between Hubs, like 3NF intersection / "associative" entities. Records are uniquely identified by two or more Hub table surrogate keys, differentiated by contextual data—for example, a "flight" would always be taken by exactly one aircraft. In contrast, a 3NF model would require an aircraft ID as a foreign key column on the flight table, meaning any changes could complicate the model and require abstract concepts with difficult to enforce data quality rules.
|
Satellite tables are used to record the context or attributes of a Hub or Link. Satellite tables only ever related to a single Hub or Link table. However, a Hub table may have multiple Satellite tables, which is especially useful when data is sourced from multiple places—for example, to record the departure and arrival times of a flight, both scheduled and actual. Unlike a 3NF model, new Satellite tables can also be added when source systems change, without additional expense or needing to back-fill data.
|
Hub columns include:
|
Link columns include:
|
Satellite columns include:
|
Data Models
Two of the core business concepts in aviation are "aircraft" and "airport". These are clearly important, widely used and understood, and easy to identify—thus should be modeled as Data Vault Hub entities.
Every flight always involves one aircraft, and is always scheduled to leave from a departure airport, bound for an arrival airport. Thus, it would be possible to model the "flight" area as a Link table joining aircraft and airport Hubs, as illustrated below:

Data Model
There are many occasions when an entity could be modeled as either a Hub or a Link. However, in this example, a "flight" is a core business concept and therefore should be modeled as a Hub. With Link and Satellite tables added, the flight setup would look more like the following example:

Data Vault Flight Model
Presentation Layer Data Model
Now that the "data warehouse" part of the model is established, the next thing to consider is how this data is used in reporting. Focusing on just the "flight" area, how could this be designed for a star schema to best support queries?
There is a clear justification for a "flight" fact table—supporting queries such as "flights by date", "origin", "destination" and "aircraft type"; core attributes such as flight times; and calculated columns such as a "delayed" flag. Calculated columns would be set according to business rules (such as actual versus scheduled flight times), and would be perfect for enabling analysis or measuring key performance indicators (KPI).

Presentation Layer Data Model
Conversely, deriving the flight's "delayed" flag from the Data Vault layer allows it to be used in any number of different star schema configurations. This would include both Type 1 and Type 2 (time variant) versions of the same data. All star schema objects can be derived from the Data Vault structures. The star schema design itself (a bus matrix) can then be altered as needed without significant rework. In fact, the star schema doesn't even need to be physically materialized, as it can simply be made up of a layer of views.
Matillion Implementation

DV DLL
As with most Matillion ETL implementations, a standalone job to be run once (only), which creates the permanent cloud data warehouse objects—namely Data Vault and star schema. For ease of reading, the Data Vault tables in the example are grouped into Hubs, Links and Satellites. Once the tables have been created, the corresponding star schema views can be added.
Since the Hub and Link tables are very narrow, there's a strong argument for distributing these across all nodes rather than by the hub surrogate key. This is a tuning option that you should consider when planning the physical layout of the Data Vault.
Please Note
The Orchestration Job used in this example can be opened via the Navigation Panel by clicking Data Vault Example → DV 1 - Setup → DV DLL.
Extract and Load

DV Extract and Load Data
In the example, data is extracted and loaded from the sample flight and plane data set provided by Matillion ETL, available via Amazon S3. However, other implementations will almost certainly be an incremental load, and probably taken from a variety of data sources.
Please Note
The Orchestration Job used in this example can be opened via the Navigation Panel by clicking Data Vault Example → DV 2 - EL → DV Extract and Load data.
Transform

DV AAA Xforms
Once extraction and loading is complete, the current (or incremental) data will become available in the staging area as database tables—namely Preparation, Hub Load, Link Load and Satellite Load. The data is then divided It can then be transformed into shape using Transformation Jobs.
Please Note
- The Orchestration Job used in this example can be opened via the Navigation Panel by clicking Data Vault Example → DV 3 - T → DV AAA Xforms.
- In the example, no distinction has been made between "raw" and "business" Data Vault structures. The derivations and business rules are applied at the same point—during initial data preparation.
Preparation
In the Preparation stage, the transformation involves two main steps:
- Ensure the data is fit for ingestion into the Data Vault—with clear business keys, no duplicates and business rules enforced to set any missing values
- Derivation of extra information—for example, the "delayed" flag is present on every flight

DV Prep Flights
The flight data preparation is fairly typical, using the Calculator component to tidy up datatypes and apply business rules. Deduplication is performed using an analytic ROW_NUMBER function inside a Calculator component.
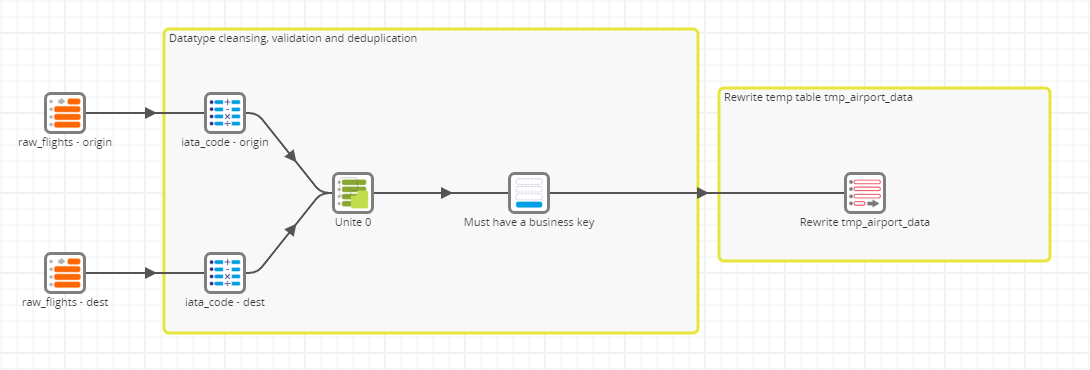
DV Prep Airport
The airport data load then uses the Unite component (and its Remove duplicates property) to get the cloud data warehouse to do the hard work of removing duplicate data.
Please Note
The Transformation Jobs used in this example can be opened via the Navigation Panel by clicking Data Vault Example → DV 3 - T → DV Prep Flights and DV Prep Airport.
Hub Load
All Hub tables can be loaded in parallel since Data Vault guarantees there are no inter-dependencies between them. In the example, the airport Hub load is a typical example, and illustrates some commonly used techniques.
Please Note
As mentioned earlier in this document, the purpose of a Hub table is to keep a permanent record of a natural business key and the central theme of a relationship. The most important technical factor, then, is to ensure that the business key is recorded correctly and there are no duplicates.

DV xforms h_airport
The Except component entitled "New h_airport" guarantees uniqueness by getting the cloud data warehouse to do the hard work of filtering out all airport records which are already known and present. This ensures incremental loads do not create duplicates.
New surrogate keys are created using a combination of an analytic ROW_NUMBER function and a SQL MAX to find the largest surrogate key already present. This ensures there are no gaps in the surrogate key sequence.

DV xforms h_aircraft
The aircraft Hub load follows a very similar pattern, but includes a Unite component to include aircraft involved in flights but not present in the aircraft reference data.
The example also illustrates how Matillion deals with late arriving dimensions in a Data Vault model. It neatly avoids the problems of having to make retroactive changes that can occur with two-tier data architecture.
Please Note
The Transformation Jobs used in this example can be opened via the Navigation Panel by clicking Data Vault Example → DV 3 - T → DV xforms h_airport and DV xforms h_aircraft.
Link Load
New records in all the Link tables can be added once the Hub updates are completed. They can then all be loaded in parallel since Data Vault guarantees there are no inter-dependencies.
Link load transformations typically start with the records which identify the relationship, and join to two or more Hub tables to acquire the necessary surrogate keys.

DV xforms l_flight_aircraft
If the relationship changes over time, there will be no issues adding multiple Links between the same Hub tables. The load_timestamp column can always be used to find the latest relationship. Alternatively, a Satellite table could be used to provide additional context and full-time variance.
Please Note
The Transformation Jobs used in this example can be opened via the Navigation Panel by clicking Data Vault Example → DV 3 - T → DV xforms l_flight_aircraft.
Satellite Load
The final stage of the Data Vault load, and often the largest, is the Satellite table update. It is made up of two main features:
- Join to the Hub table to utilize its surrogate key
- Compare with the latest Satellite record for any changes
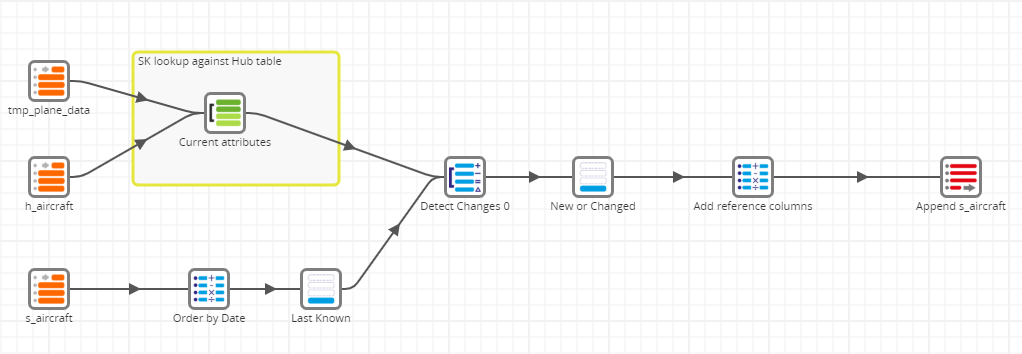
DV xforms s_aircraft
The order of the loads guarantees that every necessary Hub table is already in place, so the Hub table join can be inner.
A Detect Changes component is used to compare newly loaded, current columns against the latest version of the Satellite data. Only new or changed records are relevant, so these are filtered before being appended into the "s_aircraft" table. Inserts take advantage of an identity column to provide a unique identifier. The resulting data captures how contextual data related to the Hub has changed over time, and enables the automatic creation of time variant dimensions.
Please Note
The Transformation Jobs used in this example can be opened via the Navigation Panel by clicking Data Vault Example → DV 3 - T → DV xforms s_aircraft.
Star Schema implementation
The middle-tier Data Vault structures are just ordinary relational database tables, and could be queried directly for reporting purposes. But it's usually more convenient for end-users to use a star schema presentation layer. The Data Vault contains enough information to build these structures. This could easily be accomplished by writing some more Transformation Jobs and running them once the Data Vault loads have completed. However, there is actually no need to physically materialize any data at all.
The following example demonstrates how to set up a layer of views which look like star schema tables, but in fact have zero maintenance cost, zero storage costs and high flexibility. This is done by having dimensional views based on the same underlying data, representing three different "viewpoints"—namely a type 1 dimension, a type 2 dimension and a fact table.
Please Note
The Transformation Jobs used in this example can be opened via the Navigation Panel by clicking Data Vault Example → DV 1 - Setup → Presentation → DV_D_Flight, DV_D_Flight_TV and DV_F_Flight.
D_Flight: a type 1 dimension
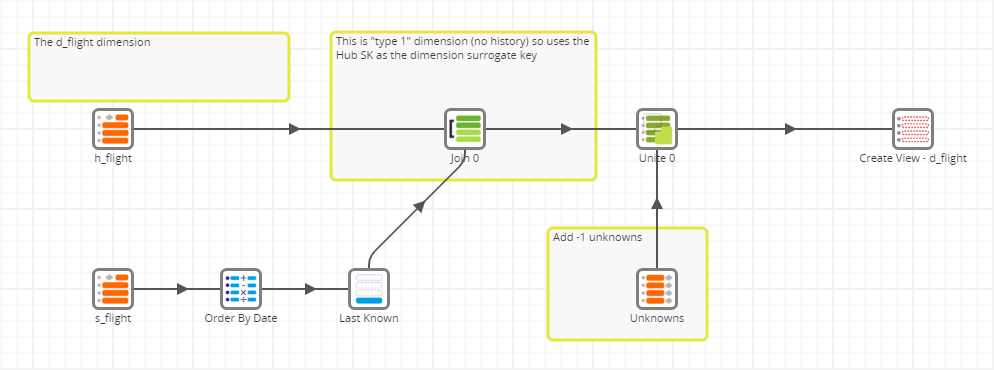
DV_D_Flight
This dimension simply shows the latest contextual information for every flight. It uses an analytic function to filter the "s_flight" Satellite to only show the most recent data. Since this will guarantee there will be only one record per Hub, the dimension surrogate key can simply be the Hub's surrogate key. This information will be used later when populating the fact table. A Fixed Flow component is also used to add the fixed, special-purpose value -1 meaning "unknown".
D_Flight_TV: a type 2 dimension
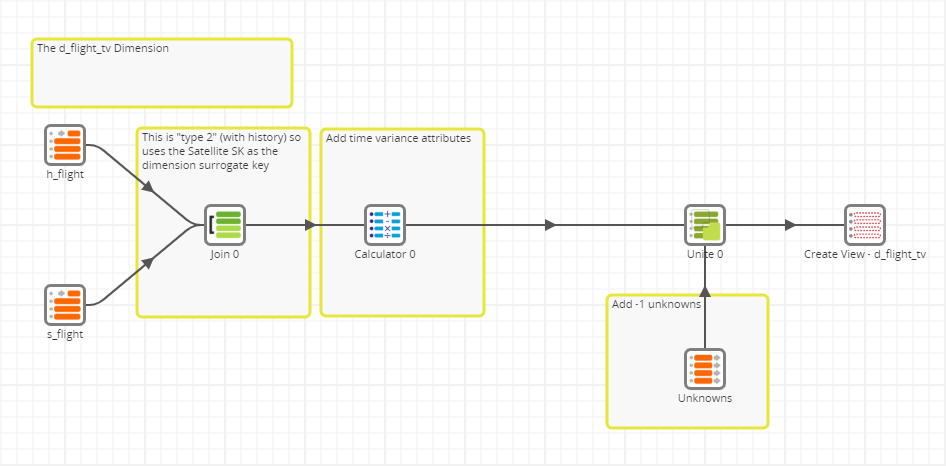
DV_D_Flight_TV
This dimension is time variant, meaning there are separate records for every version of a flight recorded over time. The data flow is actually simpler than the non-time-variant version, because it can use every Satellite record, taking advantage of the associated timestamp to derive the time variance attributes.
A Calculator component contains analytic functions to create three extra time variance columns for every row:
- Version: uses
ROW_NUMBERand is ordered by the record timestamp - Valid To: uses
LEADand is ordered by timestamp, subtracting one second from the next timestamp in the series - Current Flag: uses
ROW_NUMBERand sets to Y only if it is the last update in the sequence
This will alleviate any overlapping time-ranges, multiple "current" records and other data integrity issues, especially those associated with manually maintained time-variant dimensional structures.
Please Note
As there may be multiple versions over time, the dimension surrogate key must be the Satellite's surrogate key.
F_Flight: a fact table

DV_F_Flight
This creates a flight fact table from the same Data Vault structures and follows a similar pattern to the dimensions. The H_Flight table then defines the granularity, guaranteeing there will always be exactly one fact record per flight.
Two different join techniques are needed to set up the foreign keys to the dimensions:
- For time-variants dimension, such as "D_Flight_TV", it is necessary to use the latest Satellite record (earlier the Satellite table's surrogate key was used as the dimension key).
- For non-time-variant dimensions, it is sufficient to left-join to the relevant Data Vault Link table. This contains the associated Hub surrogate key (used earlier as the dimension key).
Summary
At this point, you now have a fully functional three-tier data warehouse, using:
- A Data Vault model as the middle tier
- A star schema presentation layer, made entirely of views, which requires no storage, loading or maintenance