Data Loader overview🔗
Data Loader is a SaaS platform that specializes in data loading tasks, extracting data from data sources and loading that data into your preferred cloud data platform destinations. It offers a range of features to ease the data loading process and empower users without extensive coding knowledge. Some features of Data Loader include:
- No-code pipeline creation: Data Loader enables you to design data pipelines without the need for coding. This feature allows more users to participate in the design of a data pipeline and accelerates the overall development time.
- Single platform for batch and change data capture pipelines: With Data Loader, users can manage both batch loading and change data capture (CDC) pipelines in a single platform. This eliminates the need for multiple tools from different vendors, simplifying the data loading process.
- Integration with Matillion ETL: Data Loader seamlessly integrates with Matillion ETL, which is a comprehensive extract, transform, and load (ETL) tool. This integration allows users to leverage pre-built data transformations provided by Matillion ETL.
How it works🔗
CDC🔗
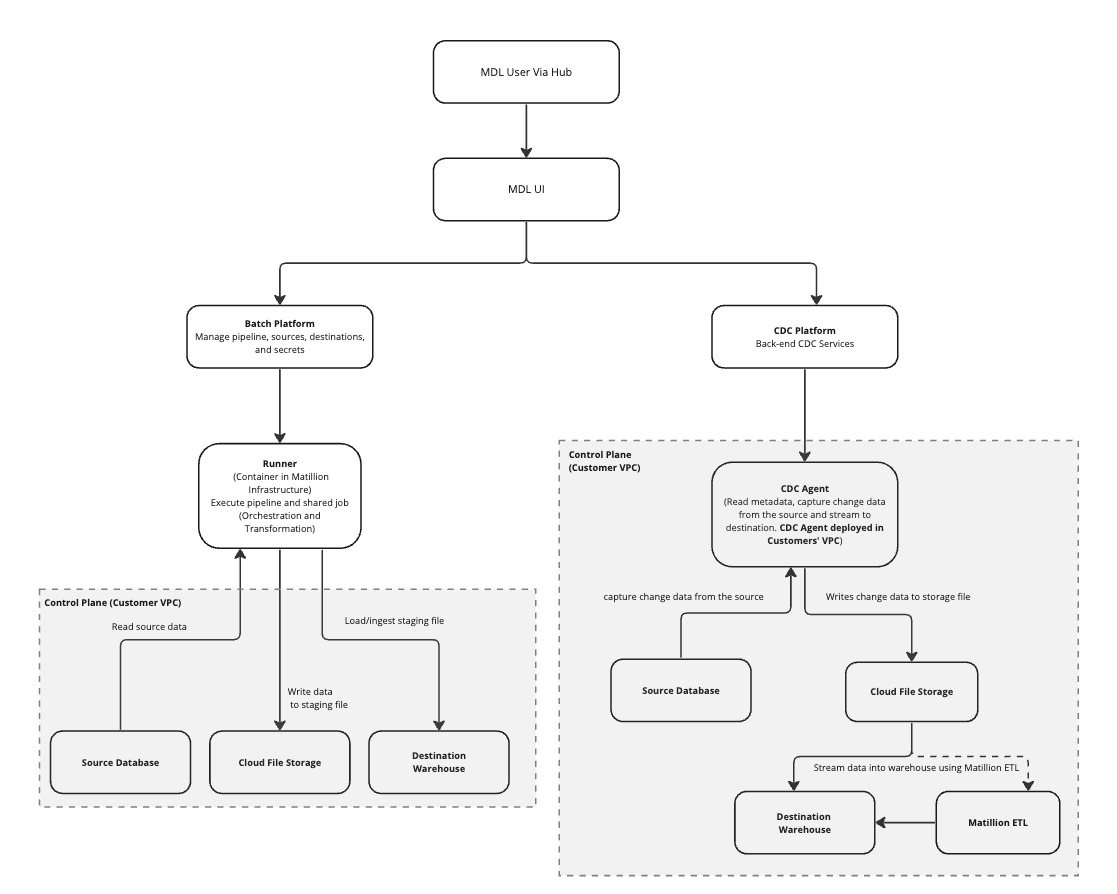
Data Loader also supports CDC loading, which provides a Hybrid SaaS, log-based data loading experience. CDC loading captures real-time change events from enabled source databases and loads the "change data" into cloud data platform destinations in near real time. This method ensures that data changes are replicated quickly and accurately.
An advantage of Data Loader's CDC capabilities is its ability to capture and replicate all change events in near real time. It maintains an immutable history of all change events, allowing users to recreate the exact state of the data at any specific point in time. By integrating with Matillion ETL, users can transform the raw change data into analytics-ready format, enabling various use cases such as fraud detection, marketing personalization, e-commerce recommendations, compliance auditing, AI/ML modeling based on current and historical data, and more.
Architecture reference🔗
Getting started🔗
- Register for a Maia account.
- In the left navigation, click the Data Loader icon
 to display the Pipelines page.
to display the Pipelines page.
Data Loader process flow🔗
Data Loader provides an intuitive and streamlined process to create data pipelines. After choosing the data loading technique, setting up a new data pipeline entails three phases.
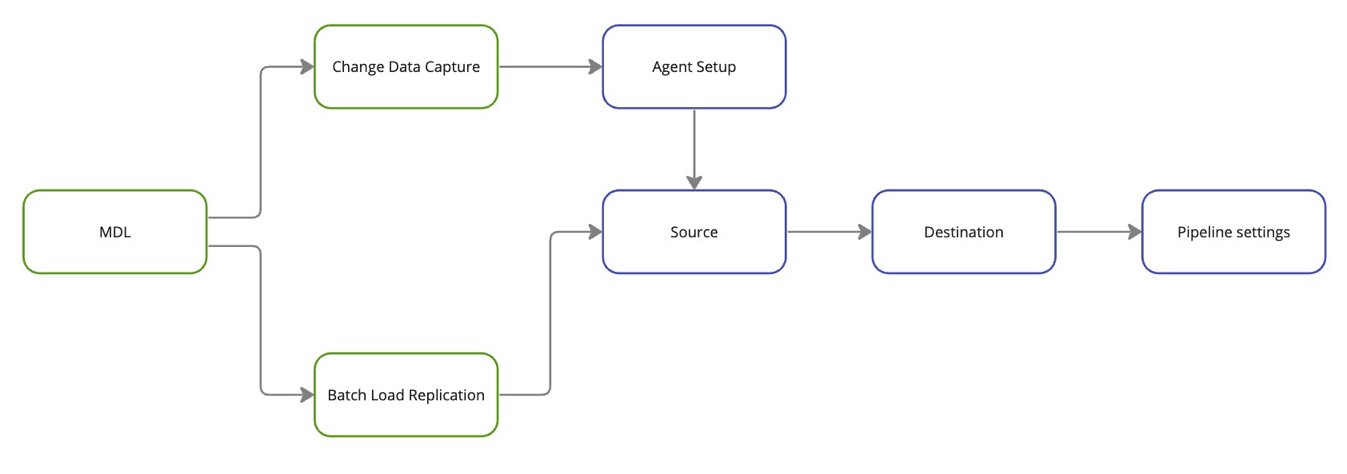
- Identify the source and schema to extract:
- In the first step, you need to specify the source database and then choose schemas/tables you want to extract data from.
- A source can be a database, a SaaS-based application (an API endpoint), or file storage containing the data that you want to load into a destination cloud data platform.
- Data Loader provides pre-built connectors to popular data sources like Salesforce, Facebook, Google Analytics, PostgreSQL, Oracle, MySQL, Excel, Google Sheets, and many more.
- Identify the destination where you want to load the data:
- Once you have identified the source and tables, the next step is to determine the destination where you want to load the extracted data.
- Data Loader supports popular cloud data lake, lakehouse, and data warehouse destinations—including Snowflake, Delta Lake on Databricks, Amazon Redshift, Google BigQuery, Amazon S3, and Azure Blob Storage.
- Pipeline settings:
- Frequency for batch pipeline generation: This setting allows you to specify how often you want the batch pipeline to be generated. It determines the time intervals at which Data Loader will fetch data from the source and load it into the destination. You can choose from options like hourly, daily, weekly, monthly, or custom intervals based on your requirements. Selecting the appropriate frequency ensures that your data pipeline runs at regular intervals to keep your destination data up to date.
- Schedule pipeline runs: Along with setting the frequency for batch pipeline generation, you can also schedule when the pipeline runs should be executed. This setting enables you to define the specific days and times when the pipeline should start extracting and loading data. You can set up a one-time schedule or create recurring schedules, depending on your data pipeline needs. Scheduling pipeline runs allows for automation and ensures data is processed and loaded at the desired times without manual intervention.
- Enable/disable snapshotting: Enable or disable the snapshotting phase for a specific source. The snapshotting phase refers to the initial capture of the source data before capturing and replicating incremental changes. Enabling the snapshotting phase allows you to take an initial snapshot of the source data, ensuring that you have a complete starting point for the subsequent CDC process. On the other hand, disabling the snapshotting phase means that the CDC process will not take an initial snapshot of the source data. Instead, it will start capturing changes from the current state of the source data onwards.
For CDC, you will also need to create a CDC agent. Read CDC agent installation for more details.