System variables🔗
System variables provide statistical and referential data about a component's execution after a pipeline has run. You can make use of system variables in:
- Component parameters.
- Python, Bash, and SQL scripts.
- Component post-processing.
System variables are read-only and cannot be modified manually. Instead, system variable values are updated automatically during component executions.
Examples of system variables include row count, execution status, execution duration, pipeline name, and project ID. For more information, read the full list of system variables.
You may wish to make use of system variables for inline business logic, such as ensuring a table row count is greater than 0; or to perform custom status reporting, such as via a webhook or email; or for auditing purposes to capture relevant metrics via a shared pipeline.
Video example🔗
Expand this box to watch our video about using system variables.
Video
System variable context🔗
Each system variable is applicable in a certain context. For example, .pipeline.name is accessible in parameters and scripts, because it is known before execution, whereas .thisComponent.message is only available in post-processing, because it is generated during execution. System variables containing task execution details can only be accessed in post-processing.
Each component in Designer has a Post-processing tab where you can map your user-defined pipeline variables and project variables to system variables.
Accessing system variables🔗
System variables can be accessed in most places where user-defined variables are used, such as component parameters, script components, and expressions. However, some system variables—specifically those under .thisComponent, such as rowCount—are only available in the Post-processing tab because they are generated during component execution. For more information, read Post-processing.
For example:
- General system variables like
.pipeline.nameand.project.idare available throughout a pipeline. - Execution-specific variables like
.thisComponent.rowCountor.thisComponent.statusare only accessible in Post-processing after the component has run (been executed).
System variables syntax🔗
You can reference a system variable in a component property using the same ${} notation syntax as in user-defined variables. For more information, read Variables.
The ${} syntax provides access to various execution metrics, such as row count, status, and system constants such as environment name and project ID. All system variables are prefixed with sysvar..
System variables follow a specific notation format:
${sysvar.<system_variable_name>}
Example:
${sysvar.thisComponent.rowCount}
This returns the row count of the records processed by a component.
List of system variables🔗
This table lists the system variables currently available for use in post-processing.
| System variable | Description |
|---|---|
| .artifact.versionName | Returns the version name of the artifact being executed. For schedules, API executions, and invocations in a shared pipeline, this corresponds to the version name provided during publishing. For runs in Designer, it is a dynamically generated UUID (since there is no version name in this scenario). |
| .environment.defaults.database | The default database configured for the environment. Supported platforms: Snowflake, Redshift. |
| .environment.defaults.schema | The default schema configured for the environment. Supported platforms: Snowflake, Databricks, Redshift. |
| .environment.defaults.warehouse | The default warehouse configured for the environment. Supported platforms: Snowflake, Redshift. |
| .environment.defaults.role | The default role configured for the environment. Supported platforms: Snowflake. |
| .environment.defaults.catalog | The default catalog configured for the environment. Supported platforms: Databricks. |
| .environment.defaults.compute | The default compute resource configured for the environment. Supported platforms: Databricks. |
| .environment.defaults.computeId | The default compute resource ID configured for the environment. Supported platforms: Databricks. |
| .environment.defaults.s3Bucket | The default S3 bucket configured for the environment. Supported platforms: Redshift. |
| .environment.defaults.application | The default application configured for the environment. Supported platforms: Redshift. |
| .environment.name | Name of the environment the pipeline is being executed in. |
| .project.id | ID of the project the pipeline is being executed in. |
| .rootPipeline.executionId | The execution ID of the top level pipeline being triggered. |
| .thisComponent.rowCount | Row count of the records loaded in the current component task execution. |
| .thisComponent.startedAt | The starting timestamp of the current component task execution, in the ISO 8601 format UTC timezone, for example, 2024-11-11T11:26:06Z. |
| .thisComponent.mainTaskFinishedAt | The main task finishing timestamp of the current component task execution, in the ISO 8601 format UTC timezone, for example, 2024-11-11T11:26:06Z. Note that the Task History finish time will also include any post-processing time, which, while minimal, may mean that that value may be slightly different to the value returned in this system variable. |
| .thisComponent.mainTaskDurationMs | The duration of the main component task execution in milliseconds. Note that the Task History duration will also include any post-processing time, which, while minimal, may mean that that value may be slightly different to the value returned in this system variable. |
| .thisComponent.message | The Task message of the current component task execution. |
| .thisComponent.status | The status message of the main component task execution. |
| .thisComponent.name | Component name of the current component task execution. |
| .thisComponent.taskId | Execution ID of the current component task execution. |
| .thisPipeline.fullName | Full name of the current pipeline, including the full folder path and file extension. |
| .thisPipeline.executionId | Execution ID of the current pipeline execution. Where the current pipeline is the root pipeline, the ID will be the same as the .rootPipeline.executionId. |
| .childPipeline.vars. |
Retrieves the value of a user-defined variable from a child pipeline, allowing parent pipelines to access and use dynamically set variables from their child executions. Example: ${sysvar.childPipeline.vars.<var_name>}. |
Component-specific system variables🔗
In addition to the general system variables listed above, certain components have their own specific system variables. These provide more granular insights into component execution, and this list will expand as more functionality is added. These variables are available in post-processing and follow the same syntax format: ${sysvar.thisComponent.<system_variable_name>}.
| Component | System variable | Description |
|---|---|---|
| SQL Script (Orchestration) (Snowflake only) | .thisComponent.queryId |
Returns the Snowflake query ID generated during component execution. Useful for auditing or debugging query behavior. |
| Table Update (Snowflake only) | .thisComponent.rowsUpdated |
Number of rows updated by the component during execution. |
| Table Update (Snowflake only) | .thisComponent.rowsInserted |
Number of rows inserted by the component during execution. |
| Table Update (Snowflake only) | .thisComponent.rowsDeleted |
Number of rows deleted by the component during execution. |
| Append To Grid | .thisComponent.rowsAdded |
Total number of rows successfully appended to the grid during the current component task execution. |
| Remove From Grid | .thisComponent.rowsRemoved |
Total number of rows successfully removed from the grid during the current component task execution. |
Examples:
${sysvar.thisComponent.queryId}
${sysvar.thisComponent.rowsUpdated}
These component-specific variables allow for more advanced logic, such as tracking record-level changes, building conditional flows based on SQL execution behavior, and enhancing audit logs.
Retrieving scalar variables from a child pipeline🔗
In the Post-processing tab, you can retrieve values of shared and public scalar variables from a child pipeline using the following components:
Syntax🔗
To access a child pipeline variable, use the format:
${sysvar.childPipeline.vars.<var_name>}
For example, if a child pipeline has a variable named var1, you can reference it as:
${sysvar.childPipeline.vars.var1}
System variables in scripts🔗
System variables have specific availability rules when used within scripts:
- System variables can be referenced in Bash and Python scripts executed in pushdown mode using the Python Pushdown and Bash Pushdown components.
- System variables are available as contextual variables in scripts:
- In Python, system variables retain the same name as listed above, but curly braces are not needed (for example,
sysvar.thisComponent.name). - In Bash, system variables are not available in the same way. Instead, you must manually pass them as arguments or assign them to user-defined variables beforehand. Bash only supports the standard
${}syntax for variable substitution.
- In Python, system variables retain the same name as listed above, but curly braces are not needed (for example,
- System variables are available as contextual variables in scripts:
- System variables are available in SQL script (orchestration) and SQL (transformation) components where queries are written inline.
- System variables are not directly available in SQL scripts that reference external files. This is because their names are not guaranteed to be compatible with the cloud data processing (CDP) engine variable names, and there is no override mechanism.
- To use system variables in file-based SQL scripts, manually map them to user-defined variables using the Post-processing tab in a prior component or by utilizing an Update Scalar component.
Example: Using system variables in post-processing🔗
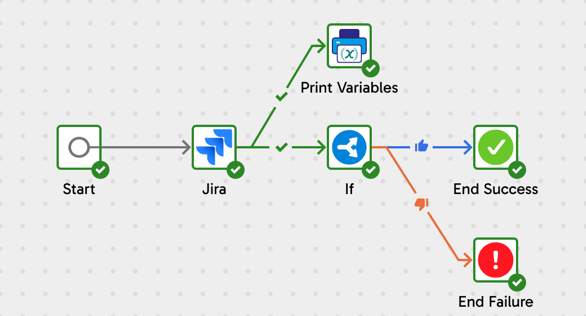
The following example uses a simple orchestration pipeline to demonstrate the effectiveness of using system variables and post-processing. In this pipeline, we will connect to Jira, extract and load a table of issues, and then use an If component to read a user-defined variable's value and set the pipeline's end state to success or failure. The user-defined variable will be mapped to a system variable using the post-processing capabilities in Designer.
This example uses the following components:
- Start: this is the starting point of any orchestration pipeline.
- Jira Query: this is the connector we'll use to extract and load data, and which we'll base our system variable's value on.
- If: this is how we'll conditionally define the success or failure of our pipeline based on the value of our system variable.
- Print Variables: this will be used to print the value of our variable to the task history.
- End Success: a successful end point for our pipeline.
- End Failure: an unsuccessful end point for our pipeline.
Create a user-defined variable🔗
- In Designer, click the Manage variables icon on the canvas.
- Click Add to begin creating a new variable.
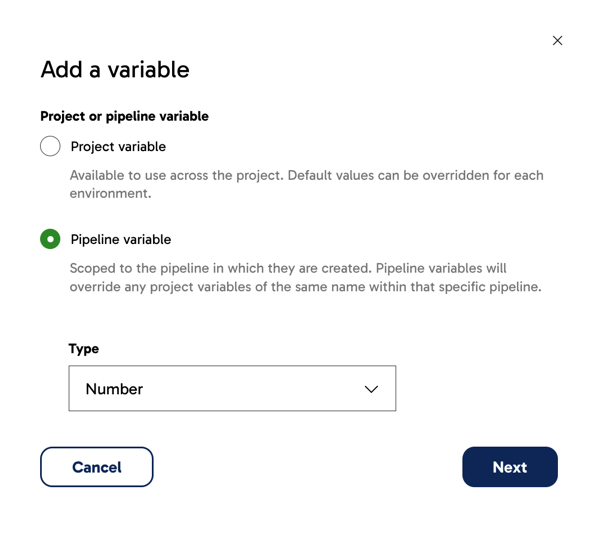
- In the Add a variable dialog, configure the basic settings of your variable.
- Select whether the variable is a project variable or a pipeline variable. Read Variable scope for more information.
- Set the variable type. Read Variable type for more information. For the purposes of this example, the scope is set to Pipeline variable and the type is set to Number.
-
Click Next.
-
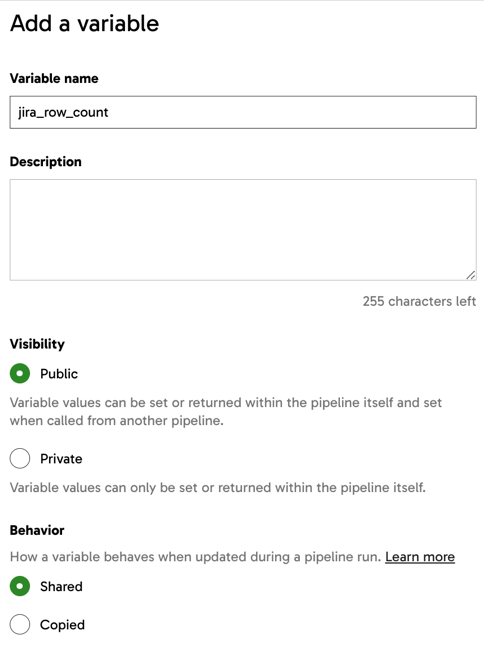
In the Add a variable panel, provide a name for your new variable. You can provide a description too, but this is optional. For this example, the Visibility and Behavior settings will be left as-is, and the default value is left blank.
- Click Create.
Set up system variables🔗
In this example, a Jira Query component is added to an orchestration pipeline to extract and load data from the Jira Issues data source.
The Post-processing tab is available in all orchestration pipeline components in the same location and works in the same manner, so using a different connector (such as Salesforce or Shopify) than Jira if you're following this example is fine.
To set up a system variable:
- Click on the orchestration component you wish to set up a system variable on. In this example, the Jira Query component is selected.
- Switch over to the Post-processing tab.
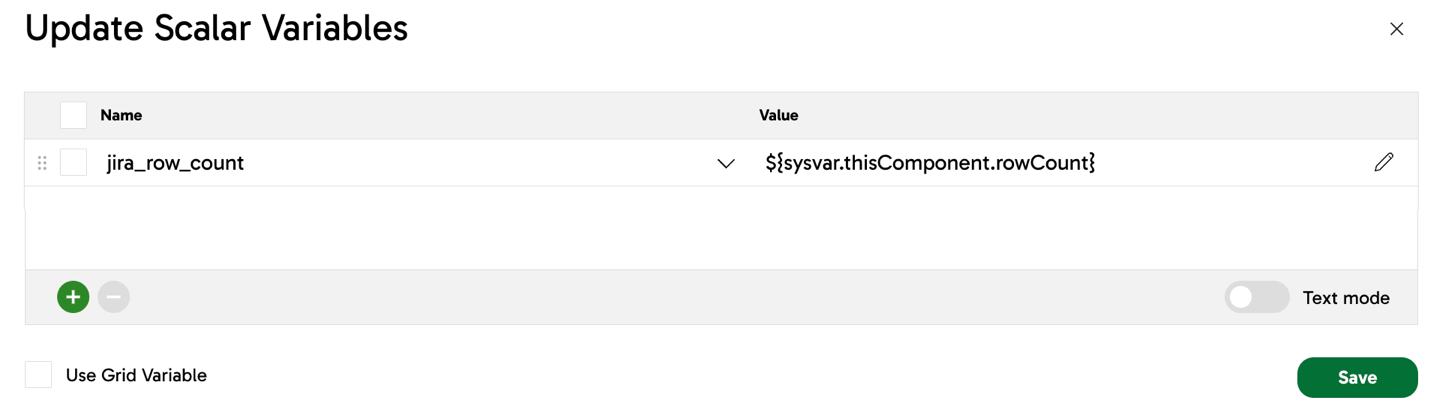
- Click into the Update Scalar Variables parameter.
- The Name column displays any existing pipeline and project variables. Select the variable you created earlier.
- The Value column is where you'll select a system variable to map your user-defined variable to.
- In the Value field, type
${sysvarto begin with, and all available system variables will be displayed. - In this example, we will use
${sysvar.thisComponent.rowCount}, a system variable that returns the row count of the component at runtime, and we're going to map this to our user-defined variable namedjira_row_count.
- In the Value field, type
- Click Save to finish setting up your system variables.
Set up Print Variables🔗
This section is optional. The Print Variables component will display the value of any specified variables at a given point in time in the Task history tab.
In this case:
- The Variables to print parameter is configured to print the value of the variable
jira_row_count. - The Prefix text parameter is left blank.
- The Include variable name parameter is set to
Yes.
Set up success and failure conditions🔗
- In this part of the example, an If component is used to define conditional logic.
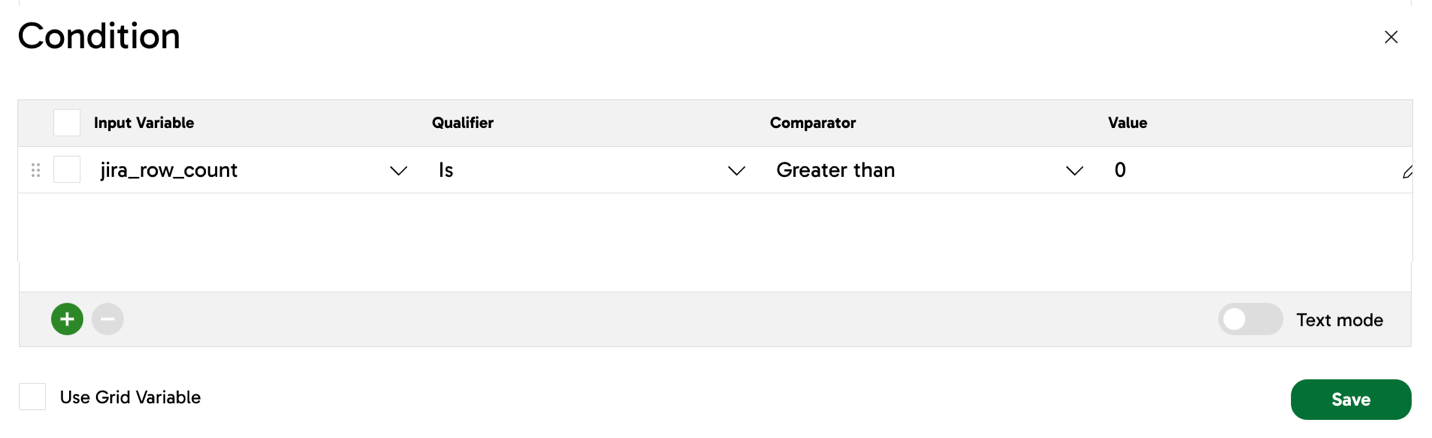
- In the If component's Condition parameter, a condition is defined. In this example, the value of our user-defined variable
jira_row_countmust be greater than0for the condition to pass as true. - When the condition is true, the If component will connect to an End Success component and finish the pipeline successfully. However, if the condition is false, the If component will connect to an End Failure component and the pipeline will fail.
Run the pipeline🔗
It's time to run our pipeline.
- Click Run.
- In the Task history tab, double-click the running task to view the task execution status of your pipeline.
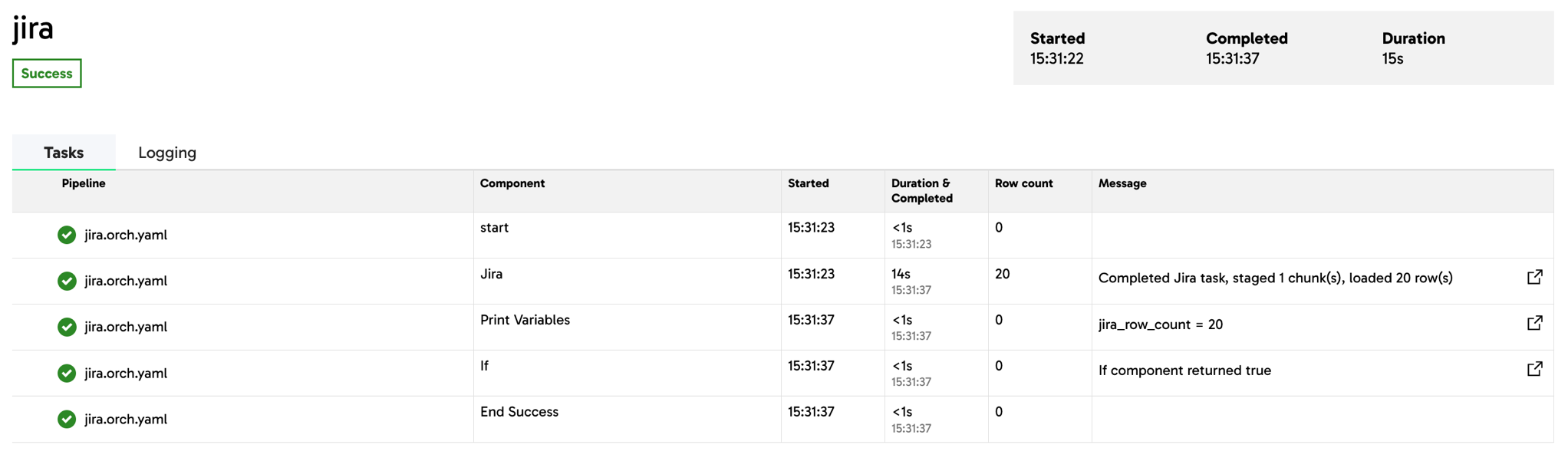
In this example, the Jira Query component loaded 20 rows of data, which meets the conditional logic of jira_row_count being greater than 0. Therefore, the If component moves forward to an End Success component, rather than the End Failure component.
The Print Variables component displays its message jira_row_count = 20, confirming the value of ${sysvar.thisComponent.rowCount}, which has been mapped to jira_row_count.
Why was this useful?🔗
A component can run successfully while loading 0 rows. For example, if the Jira Query connector remained set up correctly but was pulling data from an empty Jira project (i.e. no issues), then the connector could succeed with a row count of 0. By assigning our user-defined variable to a system variable that produces statistical and referential data and metrics about a component at runtime, we ensured that an If component could determine the success or failure of the pipeline based on the desired minimum row count value.