Lineage🔗
Maia's lineage feature provides a visual representation of data flow, showcasing the relationships between data objects and transformations. Maia enriches the lineage with valuable metadata. This includes data types, applied transformations, and source system details. This context-rich information empowers users to gain deeper insights into each element of the data flow. For more information, read Lineage.
Let's take a look at how this works and what kind of data is stored to make it happen.
Lineage flow🔗
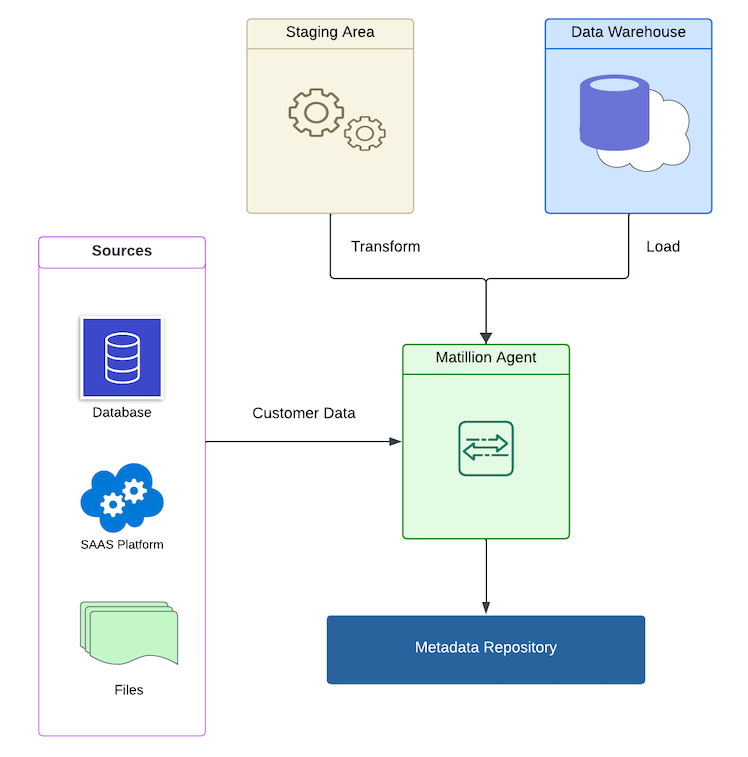
- Data originates from various sources like databases, SaaS platforms, and flat files. It first arrives at a temporary landing zone called the staging area.
- This data is then transformed using the Maia Foundation runner. This transformation stage typically involves cleaning the data, ensuring consistent formatting, and even deriving new data points.
- Crucially, the metadata repository captures information about this data's origin, any transformations applied, and its final destination. This information serves as the backbone for understanding the data's lineage.
- Finally, the transformed data is loaded into the data warehouse, a central repository that acts as the historical data hub for the organization.
This never involves accessing or storing the actual data being transported, only metadata.
Note
Lineage history is preserved to maintain a complete record of data activity. As a result, you may see pipelines, tables, or other objects in the lineage graph that have since been deleted. These objects remain visible so you can track past lineage. This helps maintain historical context and supports use cases such as auditing and compliance.