Lineage🔗
Editions
This feature is available to customers on specific editions. Visit Matillion pricing to learn more about each edition.
Lineage provides a clear, visual representation of data flow in Data Productivity Cloud pipelines, giving you insights into pipeline dependencies and relationships, and allowing you to answer questions such as:
- What was the data source?
- How has the data changed through data transformations?
- What is the final destination of the data?
Lineage offers several key benefits, including:
- Audit and compliance: Quickly track data back to its source for governance and troubleshooting.
- Impact Analysis: Understand how upstream data changes affect downstream processes. For more information, read Filtering data lineage.
- Faster Debugging: Identify issues at the source when data isn't behaving as expected.
Lineage is available for both orchestration and transformation pipelines, giving you a comprehensive view of where your data originates. Currently, only select connectors are supported. Additional connectors will be added in future releases. For more information, read Supported data sources.
Video example🔗
Expand this box to watch our video about data lineage.
Video
Accessing data lineage🔗
Lineage is collected for each dataset used in your pipelines. To access lineage:
- Log in to the Data Productivity Cloud.
- In the left navigation, click the Activity icon
 . Then, select Lineage from the menu.
. Then, select Lineage from the menu.
Lineage shows each table in your project. Listed are table names, the cloud data warehouse infrastructure (for example, Snowflake), and the cloud data warehouse location of each table.
Click a dataset's Table name to drill down to see a lineage graph for that dataset.
Note
- If you have previously used this feature, a list of tables will be displayed. Choose one to see lineage information.
- The Lineage viewer isn't a full schema view of your cloud data warehouse; it shows only those datasets that you have used in running pipelines.
Supported data sources🔗
Lineage is available for all orchestration and transformation pipelines. The following connectors are supported as data sources:
- Google Sheets
- Gmail
- Jira Load
- SurveyMonkey
- MailChimp
- MariaDB Load
- Marketo Load
- Microsoft SQL Server Load
- Netsuite Query
- Oracle Fusion Cloud Financials Load
- PostgreSQL Load
- Salesforce Load
- Shopify Load
- SugarCRM Load
- X Ads Load
- LinkedIn Ads
- Pendo
- Pipedrive
- Slack
- Zendesk Talk
- Zendesk Ticketing
We are continuously working to expand our data lineage capabilities. We plan to add support for all other connectors and data sources over time, ensuring you have a complete and accurate view of your entire data ecosystem.
Using lineage🔗
The lineage for a dataset is visually represented on a canvas in a diagram called a lineage graph. This graph depicts the various states the data undergoes as it moves through a transformation pipeline. The following example illustrates what you can expect to see in a transformation pipeline:
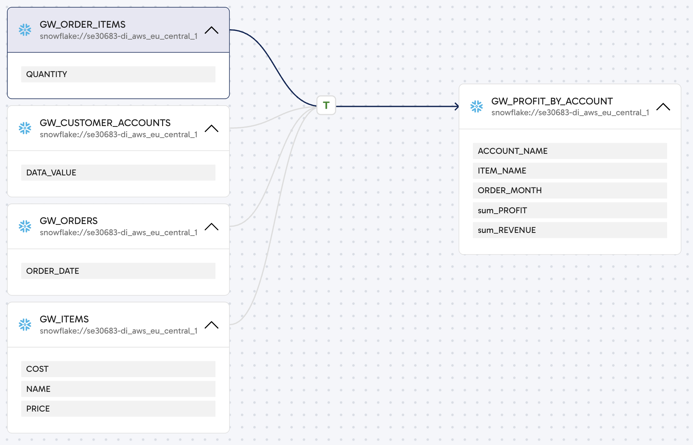
In this example, we can see that four datasets have been combined through a transformation pipeline (denoted by the T icon) to produce a target dataset. Each dataset is represented by a separate box on the canvas, and the data flow is left to right, following the direction of the arrows. The lineage graph may contain multiple datasets and multiple transformations that act on those datasets.
On this canvas, you can perform the following actions:
- Zoom in and out using the controls at the bottom-right.
- Drag the canvas around the window with your mouse.
- Drag individual boxes (datasets) around the canvas to reorganize the view (the relationships between the datasets will remain unchanged).
-
Click a transformation icon, T, to open a panel giving you the following details:
- Name of the pipeline.
- Name of the project containing the pipeline.
- Status of the most recent pipeline run (SUCCESS, FAILURE).
- Date and time that the most recent pipeline run started and finished.
- Approximate duration of the most recent pipeline run, in seconds.
- The name of the user who most recently ran the pipeline.
Click the pipeline name at the top of this panel to go to the Pipeline run details page in the Observability dashboard.
-
Click any dataset box to show information about that dataset in a panel on the right. This panel includes a Columns tab which shows the name and data type of every column in the dataset.
- Click the down arrow in any of the dataset boxes to expand the box, displaying every column in the dataset.
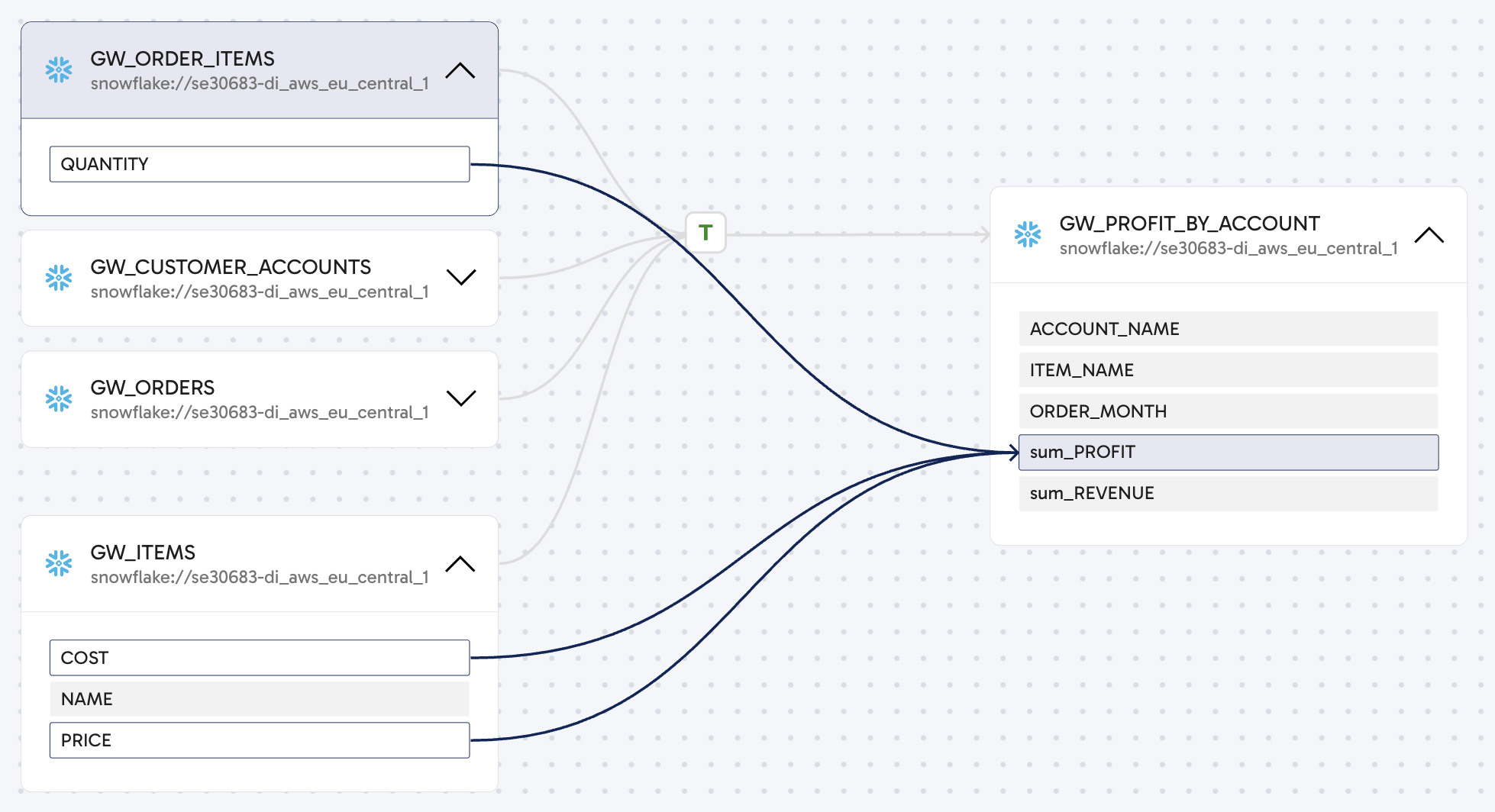
With one or more dataset boxes expanded on the canvas, you can trace the full lineage of any individual column of data. To trace a specific column, click the column name in any of the datasets. Arrows will trace that column between all the datasets in the lineage. The following example shows a simple case of this, showing the Quantity, Cost, and Price columns across two datasets before and after a transformation into sum_PROFIT.
Filtering data lineage🔗
Filtering data lineage views enhances the clarity of data flows in your pipelines. By applying filters to large datasets and pipelines, you can gain insights into the lineage without needing to view or load everything on the canvas.
What can you use lineage for?
- Upstream lineage: Quickly trace the origins of your data to perform root cause analysis, and understand how the dataset you're analyzing is constructed.
- Downstream lineage: Perform impact analysis to see which datasets or columns will be affected if you make a significant change.
To filter your lineage, use the drop-down next to Filter view located in the top-left corner of the canvas:
| Filter name | Description |
|---|---|
| Default | The lineage view is set to Default, where the critical path for your selected dataset is displayed, giving you the essential view of its lineage. |
| Upstream | This view displays relevant data and pipelines upstream of your dataset. |
| Downstream | This view displays relevant data and pipelines downstream of your dataset. |
| Complete | This view displays everything relevant to your dataset, both upstream and downstream. |
Note
You can only select one filter at a time.
Data access control🔗
Lineage metadata is collected and aggregated at the Matillion account level to provide a unified view across projects. Access is controlled by project-level user roles.
Users can view metadata only for datasets that are read from or written to by projects they belong to. If a dataset is not associated with one of their projects, they cannot access its metadata.
Data lineage API authentication and permissions🔗
To programmatically access the Data lineage API, the API credential must have the required Export lineage permission.
If a credential without this permission is used, the API returns a 403 Forbidden error.
To learn about permissions and roles, read Roles and permissions.