Building data pipelines with Maia🔗
You can use Maia to build, orchestrate, and execute data pipelines in Designer using natural language. Maia is built for a range of tasks, including preparing data via transformation pipelines, coordinating multiple pipelines with orchestration capabilities, and even executing pipelines for you, all from the Maia chat interface.
Read below to learn how Maia fits into your data engineering workflow.
Transformation pipelines🔗
Transformation pipelines are used to shape, clean, and prepare your data before it's loaded into a target destination, such as a cloud data platform (Snowflake, Databricks, Amazon Redshift) or cloud storage location (Amazon S3, Azure Blob Storage, Google Cloud Storage). These pipelines can involve tasks like filtering records, joining datasets, adding calculated fields, and writing results to tables. Instead of manually placing each component onto the canvas and configuring them yourself, you can describe your data transformaton objective and Maia will get to work.
Transformation example🔗
Note
The below prompt assumes that the objects (the table and various columns) exist in the cloud data platform that your Maia environment is connected to.
You could write the following prompt to Maia:
"Get sales data from the orders table, calculate revenue by region, and store the results in a new table called regional_revenue."
In response to a prompt like this, Maia will:
- Create or update a transformation pipeline.
- Add components such as Table Input, Calculator, and Table Output.
- Connect the components together and arrange them on the canvas in the correct order.
- Configure each component based on your instructions.
Common use cases🔗
You can use transformation pipelines to:
- Extract data from source tables or views.
- Filter, join, and enrich datasets.
- Add calculated columns, derived metrics, or business logic.
- Perform basic data validation or cleansing.
- Output results to tables, files, or downstream pipelines.
Note
You can iterate on your pipeline by giving follow-up prompts, such as "Add a margin column" or "Filter for US customers only." As long as you're in the same session, Maia understands the current state and will update your pipeline.
Example prompts🔗
- "Join orders with customers, and calculate average spend per customer."
- "Filter out rows where region is null, then sort by revenue."
- "Take the cleaned_sales table and write it to Snowflake."
- "Create a margin column using (revenue - cost) / revenue."
Orchestration pipelines🔗
Maia supports the ability to design orchestration workflows using natural language instructions. Instead of configuring each component yourself, you can describe the workflow at a high level, and Maia will build it by linking orchestration components together in the correct sequence on the canvas.
Orchestration example🔗
Note
The below prompt assumes that the objects (the table and various columns) exist in the cloud data platform that your Maia environment is connected to.
You could write the following prompt to Maia:
"Extract sales data from Salesforce, transform it using the clean_sales pipeline, then load it into Snowflake."
Maia can iteratively build orchestration pipelines, including:
- Connectors (data sources, destinations)
- Actions (job triggers, API calls)
- DDL operations (table creation or updates)
- Control logic (conditional branches, loops)
- Iterators
- Scalar variables
As you build an orchestration pipeline, Maia prompts for any required details, like secrets or credentials, to continue building the pipeline.
Example orchestration prompts🔗
- "Extract sales data from Salesforce, transform it using the clean_sales pipeline, then load it into Snowflake."
- "Run the ingest_customers pipeline. If it succeeds, trigger transform_customers. If it fails, send a Slack alert."
- "Create an orchestration that first creates the destination table, then runs extract_orders and transform_orders."
- "Trigger the marketing_reporting pipeline, wait for it to finish, then run update_dashboards."
What this workflow includes🔗
For a request such as:
"Create an orchestration pipeline that first creates the destination table, then runs extract_orders and transform_orders."
The orchestration pipeline might look like this:
- Create Table: Creates a table named
SALES_ORDERSin your cloud data platform if it doesn't already exist, with columns forORDER_ID,CUSTOMER_ID,ORDER_DATE,AMOUNT, andSTATUS. - Run Orchestration: Executes the
extract_orders.orch.yamlpipeline. - Run Transformation: Executes the
transform_orders.tran.yamlpipeline.
Each step runs only if the previous one succeeds. Maia automatically arranges the dependencies to ensure reliable execution.
Once this orchestration is created, Maia will follow up with helpful suggestions. Using these suggestions, you can delegate configuration to Maia or complete it manually, depending on your preference.
Multi-pipeline workflows🔗
Many data projects span multiple pipelines. For example, you might have a pipeline that extracts raw data, transforms that data into meaningful business insights, and then delivers the transfomed data to a downstream system such as a dashboard. With Maia, you can plot these steps one by one using natural language instructions and watch as Maia sets up your pipelines to run in the correct order.
Once your Maia project has a working environment connection to your cloud data platform, Maia can get to work understanding cross-pipeline dependencies and help you update or even expand your pipelines over time. Maia uses extensive knowledge of all components to add the correct components to the canvas for each step of the described task.
You could use a multi-pipeline workflow to:
- Automate daily reporting: Extract customer data, clean it, and then refresh downstream dashboards.
- Break up complex jobs: Run staging and transformation in separate pipelines, then chain them together.
- Standardize workflows: Build modular pipelines (such as for ingestion, transformation, and loading) and combine them into end-to-end flows.
Note
After Maia creates a multi-pipeline orchestration, you can continue the conversation to modify or add logic, such as inserting alerts, branching conditions, or post-processing steps.
Commit and push changes🔗
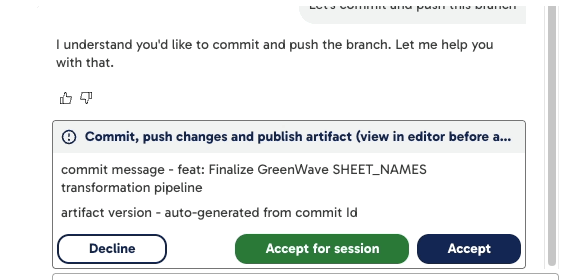
Maia can now help you commit pipeline changes and push them to your branch in a single, streamlined flow. However, Maia doesn't yet support publishing versioned artifacts.
When you request a commit (e.g., by typing "commit and push the branch"), Maia will:
- Detect the changes made to your pipeline.
- Generate a default commit message (which you can edit).
- Offer to commit and push the changes.
- Ask you to confirm the action before proceeding.
-
You'll see options such as:
- Decline: Cancel the operation.
- Accept for session: Apply the action for all similar future tasks in this session.
- Accept: Confirm this commit and push action.
Note
Artifact versions are automatically generated based on the commit ID.
This feature reduces the number of manual steps required in data ops workflows and ensures changes are consistently versioned and deployed.
Sampling data🔗
Maia can also sample your data to improve the accuracy and reliability of the transformation pipelines it creates. Sampling allows Maia to see the structure and content of a table such as columns, data types, and sample values so it can make better decisions about how to build your pipeline.
Unlike a full pipeline run, sampling is lightweight and happens only when needed.
Here's how sampling works:
- Maia will only attempt to sample data from tables that already exist in your cloud data warehouse.
-
If the table does not exist yet, because it's created in an earlier part of your pipeline, Maia will:
- Prompt you for permission to run the pipeline to materialize the table.
- Then, request permission again to sample the newly created data.
-
If the table does exist (for example, it was loaded in a prior orchestration step), Maia may automatically attempt to sample it as part of configuring your transformation components.
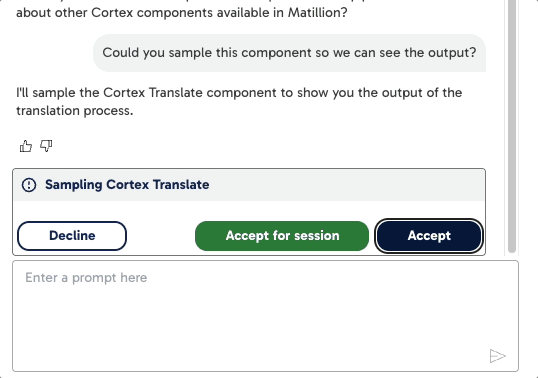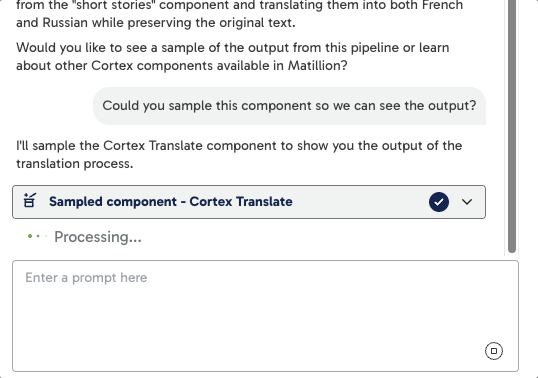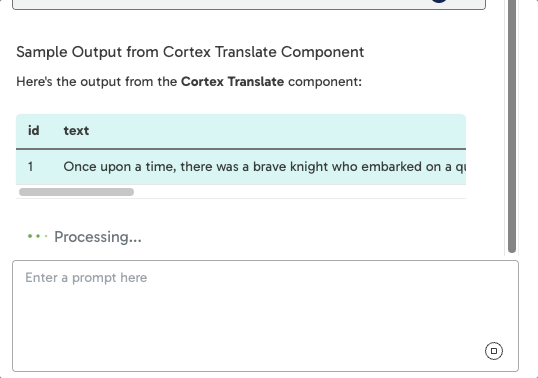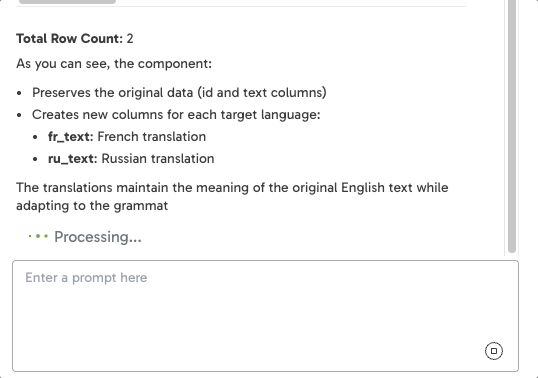
- When sampling is required, Maia uses the data sampling tool, which is visible to you in the transformation pipeline. You'll see this in the interface when Maia initiates a sample request.
Sampling helps Maia:
- Detect column names and data types.
- Choose the right components and configure them correctly.
- Apply filters, joins, and transformations more accurately.
This process happens silently while you're prompting Maia, improving the reliability of the pipelines it creates—especially when your prompts involve specific fields or business logic.
Sampling permissions🔗
Sampling is always permission-based. Maia may prompt you to allow sampling before proceeding, especially if it needs to access newly created tables. Only a small number of rows (typically 10–20) are used, and sampled data is stored for 30 days.
If you want to prevent Maia from sampling data across your entire Data Productivity Account, in your account details, disable the Enable sampling for Maia toggle.
Running pipelines🔗
Maia can run your orchestration or transformation pipelines directly from the chat interface on your instruction, letting you test and validate your workflows without leaving the conversation.
For example:
"Run the daily_ingest pipeline."
Or as part of a larger task:
"Create a new pipeline to clean customer data, then run it."
Permissions and control🔗
To run a pipeline, Maia requests explicit permission via the Tool permissions dialog:
- Accept once: Run once.
- Accept for Session: Allow runs throughout the session.
- Decline: Cancel the run.
This gives you control over pipeline execution, especially when working with sensitive data or production environments.
Monitoring and feedback🔗
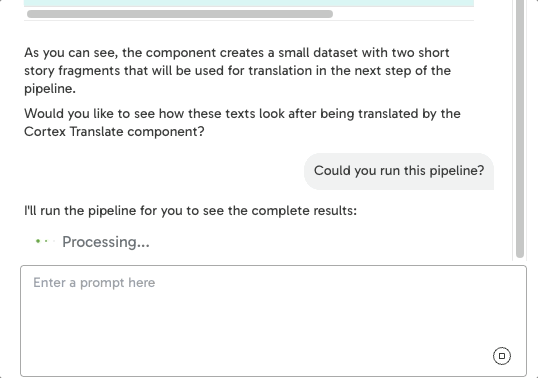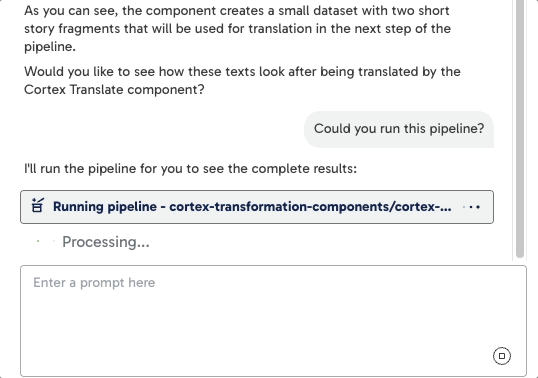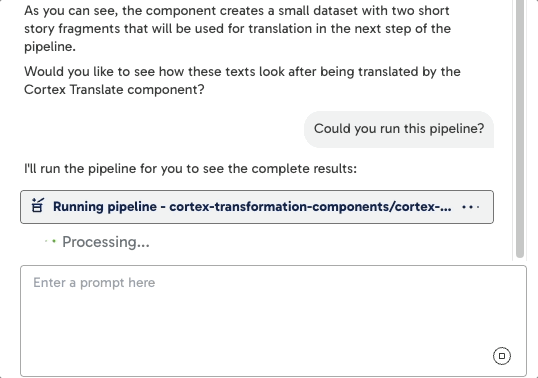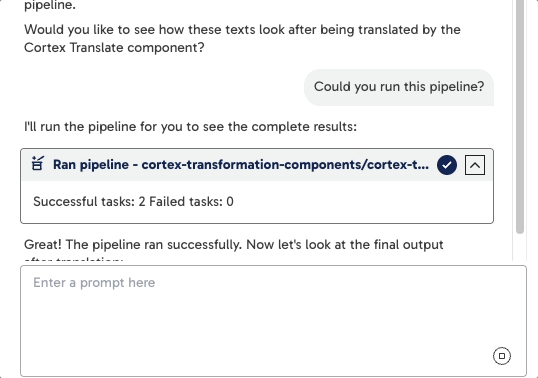
Once a pipeline is running, Maia monitors its progress and provides live updates in the chat:
- Current run status (running, succeeded, failed).
- Output summaries (such as the number of rows processed).
- Highlighting of any component errors.
You can follow up with prompts, such as:
- "What was the result of the last run?"
- "Show me any failed components."
- "Run it again with new parameters."
You can use a single session to create, run, and update pipelines, and even review results.