Matillion Change Data Capture (CDC)🔗
Matillion Change Data Capture (CDC) is a near-real-time data ingestion architecture that offers a complete end-to-end solution for capturing, transforming, manipulating, and synchronizing data. Matillion CDC combines its specific data ingestion proficiency with Matillion ETL's best-in-class data transformation and load capabilities.
Matillion CDC provides an intuitive user experience to get you designing and running pipelines against popular source databases and data lakes.
Sources currently supported are:
- Db2 for IBM i
- PostgreSQL
- Oracle
- Microsoft SQL Server
- MySQL
Reference architecture🔗
Matillion CDC is a data integration platform that offers a hybrid approach to data control by using self-hosted CDC agents. These CDC agents are responsible for capturing and handling the data. By keeping the CDC agents within the organization's infrastructure, the user retains control over their data.
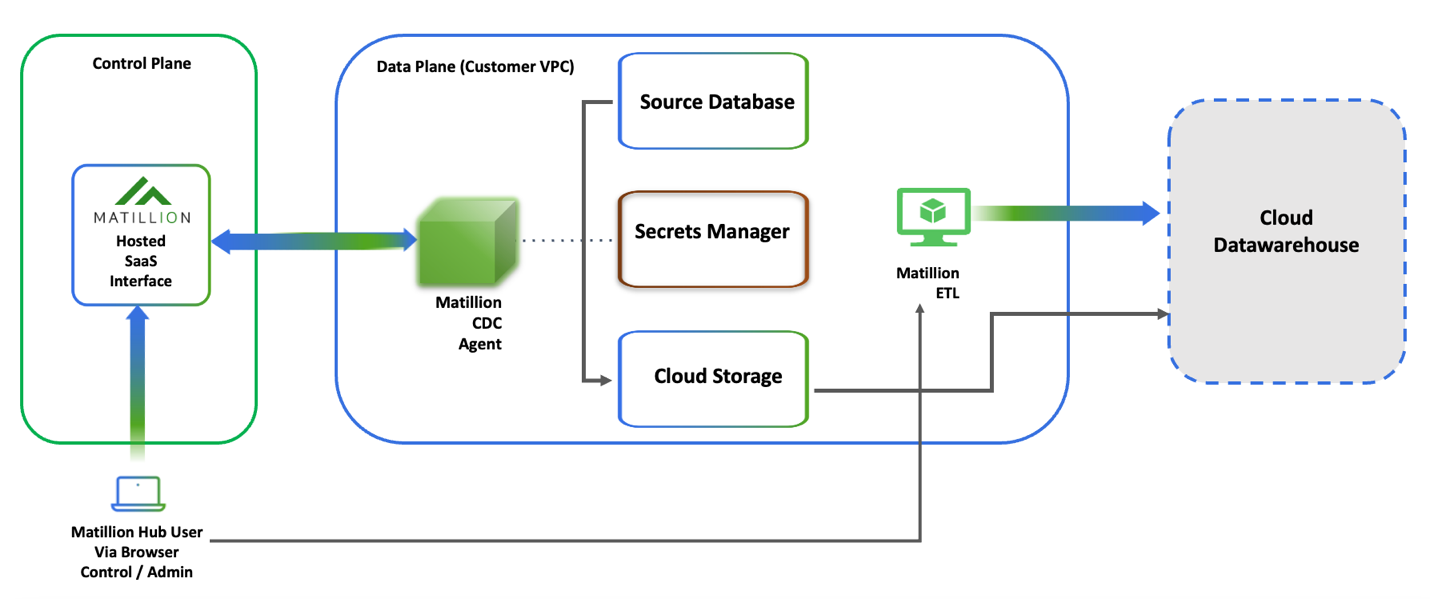
- Connecting to the source database: The CDC agent establishes a connection with the source database from where it needs to capture the data changes and track the changes in real time.
- Processing change events and writing to cloud storage: Once connected to the source database, the CDC agent processes the change events occurring in the database. It captures and transforms the data changes into manageable units and writes them out in partitioned batches in near real time. These batches are then sent to the designated cloud storage destination.
- Data stays within your private cloud: The CDC agent is deployed in your private cloud infrastructure. This means that the change data that's being streamed from the source and written to the destination by the CDC agent remains within your infrastructure.
- SaaS interface for configuration and monitoring: The Matillion CDC interface offers capabilities to configure and manage the CDC pipeline for a CDC agent. You can define the specific settings for the source database, schemas, and data snapshotting. Additionally, the interface allows you to monitor the status of the CDC pipeline, ensuring visibility into the data integration process.
- Secure connection to the Matillion SaaS platform: To enable the configuration and monitoring capabilities offered by the interface, the CDC agent establishes a secure connection back to the Matillion SaaS platform. This connection ensures secure communication between the CDC agent and the platform for configuration updates, status monitoring, and CDC agent management.
- Cloud secrets service: The CDC agent requires access to a cloud secrets service, which is a secure storage system for storing authentication and connection secrets. These secrets are used by the CDC agent to authenticate itself with the source database and establish a secure connection for capturing the data changes.
- Integration with Matillion ETL: Matillion CDC works seamlessly with Matillion ETL, a powerful data transformation and loading tool. Matillion ETL includes CDC shared jobs that are specifically designed to work with Matillion CDC. These shared jobs allow users to leverage the captured change events for various use cases, such as near-real-time data synchronization, replication, artificial intelligence, machine learning, fraud detection, auditing, real-time marketing campaigns, and cloud migration. By combining Matillion CDC with Matillion ETL, users can perform advanced data transformations and utilize the captured change events effectively.
The details for how to configure the source database and the specific capture process vary per connector. For more detail on specific source databases, refer to the corresponding CDC sources page.
The CDC agent deployment instructions can be found here.
Matillion CDC log-based transaction🔗
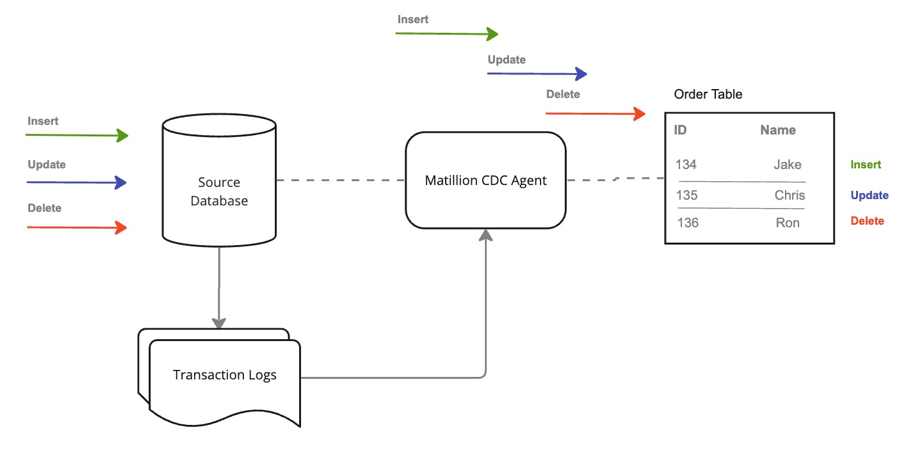
Matillion CDC offers several benefits and integration capabilities to provide a consistent and up-to-date view of the connected source database while minimizing resource usage and maintaining the regular operations of the source database.
- Low-level logs for consistent view: Matillion CDC leverages low-level logs from the source database to provide a consistent and up-to-date picture of the connected source database and the tables it is monitoring. This ensures that the captured data reflects the latest changes and provides an accurate representation of the source database.
- Minimal resource usage: The log consumption approach used by Matillion CDC keeps the resource usage on the source database to a minimum.
- Continuous operation: Once the CDC agent is configured and started, it operates autonomously without requiring much intervention. The CDC agent continually monitors all changes occurring in the source database, consumes those changes from the low-level logs, and delivers them to the designated target data lake or storage. This ensures a continuous and reliable data capture process.
Batching process🔗
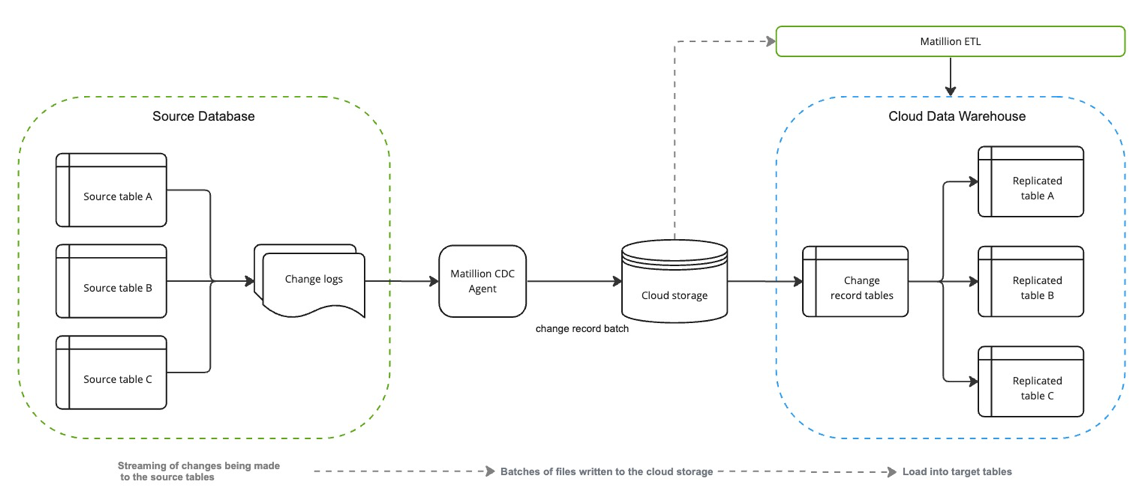
In a running CDC pipeline with Matillion CDC, the changes captured from the source database are written out to files in the specified storage destination. The process involves buffering the changes within the CDC agent before writing them to files within a partition. Here's how it works:
- Change buffering: When changes are emitted from the source database, they are buffered within the CDC agent. This buffering allows for efficient handling and processing of the changes before writing them to files.
- Partitioned files: The changes captured by the CDC agent are written to files in a partitioned manner. Partitions are logical divisions of data based on specific criteria, such as time intervals or other relevant factors. Each partition contains a subset of changes within a defined period.
- Writing files: The files containing the changes within a partition are written when one of the following conditions is met:
- Time threshold: If the oldest change in a partition reaches a specified time threshold, the changes within that partition are written to a file. This ensures that changes are not held in the buffer for an extended period.
- File size limit: If the size of changes within a partition exceeds a specified limit, the changes are written to a file. This helps maintain manageable file sizes.
By buffering the changes within the CDC agent and writing them to partitioned files based on time thresholds or file size limits, Matillion CDC ensures efficient and timely handling of data changes. The buffer time setting helps ensure that changes are processed and written within a specified time frame, maintaining near-real-time capture and minimizing any delay in data availability.
Files🔗
The generated change files are partitioned by the database table and UTC time of the change, plus each file will have a unique name. The full path description is:
<configured_prefix>/<database>/<schema>/<table>/<version>/<year>/<month>/<day>/<hour>/<filename>
Each file contains a series of change records in the Avro file format. This Avro format is a supported format for optimized ingestion into a cloud data warehouse. This is the same common structure for each source; however, variations may occur for individual keys. Each row in the file is a change record and contains the following structure (the below uses PostgreSQL as an example):
{
"before": null,
"after": {
"actor_id": "70ac0033-c25b-7687-5a86-6861c08cabdd",
"first_name": "john",
"last_name": "smith",
"last_update": 1635638400123456,
"version": 0
},
"metadata": {
"connector": "postgresql",
"db": "postgres_db",
"key": ["actor_id"],
"lsn": 37094192,
"name": "matillion",
"op": "r",
"schema": "public",
"table": "actor",
"ts_ms": 1635638400234,
"txId": 543,
"version": "1.7.1.Final"
}
}
The op field contains the type of the change for this record, r = read (during snapshot) c = create, d = delete, u = update.
The before and after fields contain the values in that row as they were before and after the change was applied, and as such the fields will differ by table. In the case where a record was created, the value for the before field will be empty and in the case where a record was deleted, the value for the after field will be empty.
CDC shared jobs🔗
The CDC agent writes the generated change files, as described above, into cloud storage. Once the change files are in cloud storage, additional processing is then required to read the data from those files and load it into a target table in your chosen cloud data warehouse. This processing is performed by Matillion ETL, using the CDC shared jobs that are provided within Matillion ETL.
CDC shared jobs are available in Matillion ETL on the following platforms:
- Snowflake
- Delta Lake on Databricks
- Amazon Redshift
- Google BigQuery
Note
Shared jobs for Azure Synapse Analytics are not currently available in Matillion ETL for Synapse on Azure.
Core concepts🔗
There are some important concepts to understand within the Matillion CDC product, these are detailed below:
| Concept | Description |
|---|---|
| CDC agent | The CDC agent is a service that needs to be deployed and configured within the user's technology stack and is responsible for securely connecting via a secrets management application to both the source database and the target cloud data lake destination. Information security is of paramount importance to Matillion, which is why the CDC agent provides a happy medium between the information reported back to the Matillion CDC SaaS platform and any sensitive data, which never leaves the user's technology stack. For further information, including installation instructions, read the Setting Up CDC agents documentation here. |
| Pipeline | A pipeline is a collection of configuration details, including the source configuration, target configuration, and any advanced properties that allow the CDC agent to begin monitoring and consuming database changes and delivering them to the appropriate data lake. There is a 1-to-1 relationship between a CDC agent and a pipeline, therefore multiple CDC agents will be required to configure and run multiple pipelines. |
| Source | The source (or source configuration) is a collection of connection properties for the source database you wish to configure a CDC pipeline for. |
| Target | The target (or destination configuration) is a collection of properties where the CDC agent will deliver change event data captured from the source database. |